原文:
www.kdnuggets.com/2022/07/12-challenging-data-science-interview-questions.html

图片来源 | Canva Pro
如果你问我,招聘经理并不在意正确答案。他们希望评估你的工作经验、技术知识和逻辑思维。此外,他们寻找的是既了解业务又掌握技术的 数据科学家。
例如,在与一家顶级电信公司的面试中,我被要求提出一个新的数据科学产品。我建议使用一个开源解决方案,并让社区参与到项目中。我解释了我的思路以及如何通过向付费客户提供高级服务来实现产品的货币化。
我收集了 12 个最具挑战性的数据科学面试问题及其答案。这些问题被分为三部分:情境问题、数据分析和机器学习,以涵盖所有方面。
你也可以查看完整的数据科学面试合集:第一部分 和 第二部分。该合集包含了关于数据科学所有子类别的数百个问题。
你不必过于担心。招聘经理想评估你处理复杂项目的经验。
从项目名称和简短描述开始。然后,解释为什么这个项目具有挑战性以及你是如何克服这些挑战的。关键在于细节、工具、方法论、术语、创新思维和奉献精神。
在面试前回顾你最近的五个项目是一个好习惯。这将帮助你准备谈话要点、业务用例、工具和数据科学方法论。
这不是一个完整的问题,可能会让面试者感到困惑。你需要询问业务用例以及基准指标的额外信息。在那之后,你可以开始分析数据和业务用例。你将需要解释统计算法来分析数据的可靠性和质量。之后,将其与业务用例匹配,并说明它如何改进现有系统。
记住,这个问题主要是评估你的批判性思维能力和处理随机数据集的准备情况。解释你的思路并得出结论。
这是一个棘手的问题,你应该准备好相关的数据和机器学习如何为多个公司创造收入的案例。
如果你对数字不太了解,也不用担心。有多种方法可以解决这个问题。机器学习用于预测股价、诊断疾病、多语言客户服务和电子商务推荐系统。
你需要告诉他们你在某一特定领域的专业知识,并将其与公司的使命匹配。如果公司是金融科技公司,你可以提出欺诈检测、预测增长、威胁检测和政策推荐系统等建议。
A/B 测试是一种用于随机实验的统计假设检验,涉及两个变量 A 和 B。它主要用于用户体验研究,通过分析用户对两个不同版本的产品的反应。
在数据科学中,它用于测试公司内各种机器学习模型的生产和数据驱动解决方案分析。

图片来源于 Optimizely
面试官会提供关于数据库表的额外信息,例如Customers表具有ID和Name数据字段,而Orders表具有ID、CUSTOMER和VALUE字段。
我们将通过ID和CUSTOMER列连接两个表,并显示ID、Name作为客户名称,以及VALUE。
SELECT a.ID,
a.Name as Customer Name,
b.VALUE
FROM Customers as a
LEFT JOIN Orders as b
ON a.ID = b.CUSTOMER上面的例子很简单。你必须为复杂的 SQL 查询做好准备,以通过面试环节。查看 Nate 最近的博客 你可能在下次面试中看到的 24 个 SQL 问题。
马尔科夫链是一种通过概率方法从一个状态转换到另一个状态的模型。它定义了基于当前状态和经过的时间,转换到未来状态的概率。马尔科夫链被广泛应用于信息理论、搜索引擎和语音识别。通过阅读 Brilliant Math’s 维基页面来了解更多信息。

图片来源于 Brilliant Math & Science Wiki
简单的解决方案是丢弃异常值,因为它们会影响整体数据分析。但在这样做之前,请确保你的数据集足够大,并且你要移除的值确实是垃圾。垃圾指的是这些值是由于错误而被添加的。
除此之外,你还可以:
-
归一化数据
-
应用 MinMaxScaler 或 StandardScaler。
-
使用不受异常值影响的算法,例如随机森林。

图片来源于 dataanalyticsedge
TF-IDF(词频逆文档频率)用于计算一个词在文本序列或语料库中的相关性。在文本索引过程中,它评估文档或语料库中每个术语的值。它通常用于文本向量化,将一行或一句话转换为数值,并用于 NLP(自然语言处理)任务。

图片由 filotechnologia.blogspot 提供
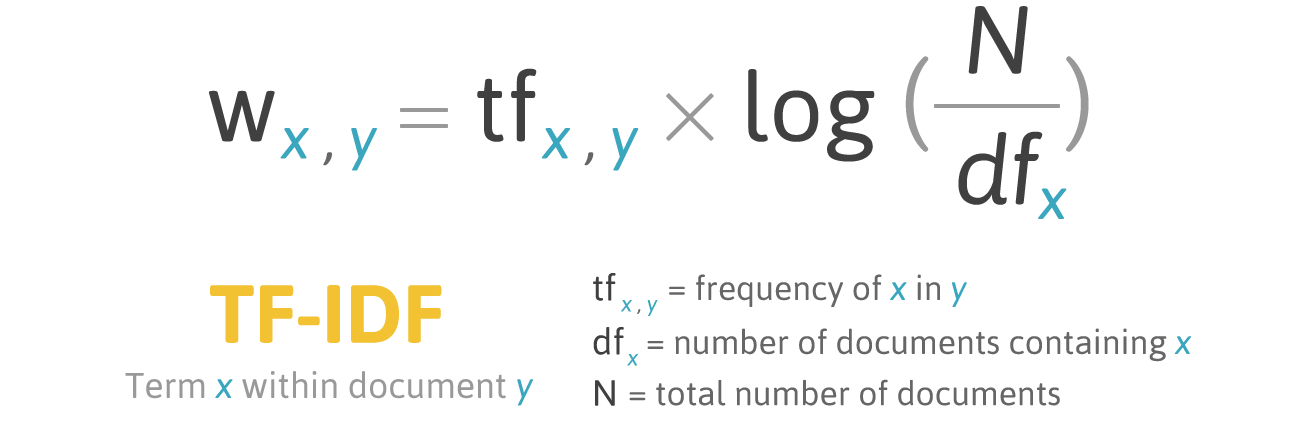{kind=link}
误差是观察值与其理论值之间的差异。通常是由数据生成过程(DGP)生成的未观察到的值。
残差是观察值与由模型生成的预测值之间的差异。
不一定。它很容易陷入局部最小值或最优点。如果有多个局部最优点,其收敛性取决于数据和初始条件。很难达到全局最小值。
滑动窗口法也称为滞后法,其中之前的时间步骤用作输入,下一时间步骤用作输出。之前的步骤取决于 窗口宽度,即之前步骤的数量。滑动窗口法在单变量预测中相当有名。它将时间序列数据集转换为监督学习问题。
例如,如果序列是 [45,96,105,108,130,140,160,190,220,250,300,400] 且 窗口宽度 是 三。输出将如下所示:
| X | y |
|---|---|
| 45,96,105 | 108 |
| 96,105,108 | 130 |
| 105,108,130 | 140 |
| 108,130,140 | 160 |
| … | … |
过拟合发生在你的模型在训练集和验证集上表现良好,但在未见过的测试集上表现不佳时。

图片由 Ilyes Talbi 提供
我们可以通过以下方式避免过拟合:
-
保持模型简单
-
避免训练过长的轮次
-
特征工程
-
使用交叉验证技术
-
使用正则化技术
-
使用 Shap 进行模型评估
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专家,热衷于构建机器学习模型。目前,他专注于内容创作,撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个 AI 产品,帮助那些遭受心理健康问题的学生。