-
Что такое реляционная база данных?
Ответ
Реляционная база данных — это набор данных с предопределенными связями между ними. Эти данные организованны в виде набора таблиц, состоящих из столбцов и строк. В таблицах хранится информация об объектах, представленных в базе данных. В каждом столбце таблицы хранится определенный тип данных, в каждой ячейке — значение атрибута. Каждая строка таблицы представляет собой набор связанных значений, относящихся к одному объекту или сущности. -
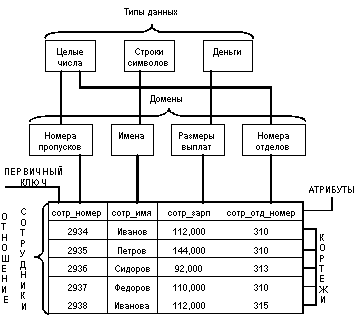
Что такое таблица, кортеж? Что такое primary key?
Ответ
Таблица — это набор элементов данных (значений), использующий модель вертикальных столбцов (имеющих уникальное имя) и горизонтальных строк. Таблица содержит определенное число столбцов, но может иметь любое количество строк. Каждая строка однозначно определяется одним или несколькими уникальными значениями, которые принимают её ячейки из определенного подмножества столбцов. Подмножество столбцов, которое уникально идентифицирует строку, называется первичным ключом(primary key).- Primary key не позволяет создавать одинаковых записей (строк) в таблице;
- PK обеспечивают логическую связь между таблицами одной базы данных.
По соглашению Rails предполагает, что для первичного ключа используется столбец id в таблице, который автоматически создается для каждой вашей записи.
Кортеж - это набор именованных значений заданного типа.
-
Как реализованы связи между таблицами? Что такое foreign key?
Ответ
Между двумя или более таблицами базы данных могут существовать отношения подчиненности. Отношения подчиненности определяют, что для каждой записи главной таблицы может существовать одна или несколько записей в подчиненной таблице.Существует три разновидности связей между таблицами базы данных:
-
«один-ко-многим»,
-
«один-к-одному»,
-
«многие-ко-многим».
Внешний ключ Foreign key, кратко FK. Обеспечивает однозначную логическую связь, между таблицами одной БД. Для обеспечения ссылочной целостности в дочерней таблице создается внешний ключ. Во внешний ключ входят поля связи дочерней таблицы. Для связей типа "один-ко-многим" внешний ключ по составу полей должен совпадать с первичным ключом родительской таблицы.
Например, есть две таблицы А и В. В таблице А (обувь), есть первичный ключ: размер, в таблице В (цвет) должна быть колонка с названием размер. В этой таблице «размер» это и будет внешний ключ для логической связи таблиц В и А.
По соглашению Rails предполагает, что столбец, используемый для хранения внешнего ключа в этой модели, имеет имя модели с добавленным суффиксом id
-
-
Как работает SELECT оператор?
Ответ
SELECT - оператор запроса, возвращающий набор данных (выборку) из базы данных.Оператор SELECT состоит из нескольких предложений (разделов):
Сам SELECT определяет список возвращаемых столбцов (как существующих, так и вычисляемых), их имена, ограничения на уникальность строк в возвращаемом наборе, ограничения на количество строк в возвращаемом наборе;
FROM задаёт табличное выражение, которое определяет базовый набор данных для применения операций, определяемых в других предложениях оператора;
WHERE задает ограничение на строки табличного выражения из предложения FROM;
GROUP BY объединяет ряды, имеющие одинаковое свойство с применением агрегатных функций
HAVING выбирает среди групп, определенных параметром GROUP BY
ORDER BY задает критерии сортировки строк; отсортированные строки передаются в точку вызова.
Синтаксис оператора SELECT:
SELECT <column_list> FROM <table_name> [WHERE <условие>] [GROUP BY <условие>] [HAVING <условие>] [ORDER BY <условие>]
-
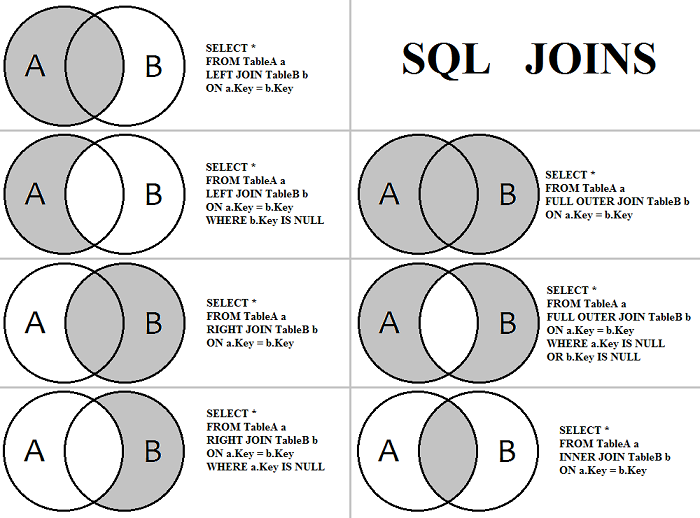
Какие бывают виды JOIN? Как каждый работает?
Ответ
INNER JOIN - оператор внутреннего соединения, соединяет две таблицы. Выбираются только совпадающие данные из объединяемых таблиц.OUTER JOIN - существует два типа внешнего объединения: LEFT OUTER JOIN и RIGHT OUTER JOIN. Работают они одинаково, разница заключается в том что LEFT - указывает что "внешней" таблицей будет находящаяся слева, а RIGHT - справа. Выбираются все данные из внешней таблицы + совпадения из второй таблицы.
Cross/Full Join - FULL JOIN возвращает объединение объединений LEFT и RIGHT таблиц, комбинируя результат двух запросов. CROSS JOIN возвращает перекрестное объединение двух таблиц. Результатом будет выборка всех записей первой таблицы объединенная с каждой строкой второй таблицы. Важным моментом является то, что для кросса не нужно указывать условие объединения.
-
Как работают INSERT, UPDATE, DELETE операторы?
Ответ
INSERT — оператор, который позволяет добавить строки в таблицу, заполняя их значениями. Значения можно вставлять перечислением с помощью слова values и перечислив их в круглых скобках через запятую или оператором SELECT.Синтаксис:
INSERT INTO table_name (column1, column2, column3, ...) VALUES (value1, value2, value3, ...);
UPDATE — оператор, позволяющий обновить значения в заданных столбцах таблицы.
Синтаксис:
UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition;
DELETE — операция удаления записей из таблицы. Критерий отбора записей для удаления определяется выражением WHERE. В случае, если критерий отбора не определён, выполняется удаление всех записей.
Синтаксис:
DELETE FROM table_name WHERE condition;
-
Что такое индексы? Для чего используются? Плюсы, минусы?
Ответ
Индекс — объект базы данных, создаваемый с целью повышения производительности поиска данных. Таблицы в базе данных могут иметь большое количество строк, которые хранятся в произвольном порядке, и их поиск по заданному критерию путём последовательного просмотра таблицы строка за строкой может занимать много времени. Индекс формируется из значений одного или нескольких столбцов таблицы и указателей на соответствующие строки таблицы и, таким образом, позволяет искать строки, удовлетворяющие критерию поиска.Ускорение работы с использованием индексов достигается в первую очередь за счёт того, что индекс имеет структуру, оптимизированную под поиск.
Для оптимальной производительности запросов индексы обычно создаются на тех столбцах таблицы, которые часто используются в запросах. Однако увеличение числа индексов замедляет операции добавления, обновления, удаления строк таблицы, поскольку при этом приходится обновлять сами индексы. Кроме того, индексы занимают дополнительный объем памяти.
-
Какие виды индексов бывают?
Ответ
"Золотое правило индексирования" — иметь индекс под каждый запрос.
Упорядоченные — индексы, в которых элементы поля(столбца) упорядочены.
-
Возрастающие
-
убывающие
Неупорядоченные — индексы, в которых элементы неупорядочены.
-
Индексы по представлению (view)
-
Индексы по выражениям (например, в PostgreSQL)
-
Некластерный индекс
-
Кластерный индекс
-
B-деревья
-
B+-деревья
-
B-деревья
-
Хеши
-
Простой индекс (индекс с одним ключом)
-
Главный индекс (индекс по первичному ключу)
-
Уникальный индекс
-
Разреженный индекс (NoSQL)
-
Пространственный индекс
-
Составной пространственный индекс
-
Полнотекстовый (инвертированный) индекс
-
Хэш-индексы
-
Битовый индекс (bitmap index)
-
Обратный индекс (inverse index)
-
Функциональный (function-based) индекс (индекс по вычисляемому полю)
-
Первичный индекс
-
Вторичный индекс
-
XML-индекс
- Полностью перестраиваемый
- Пополняемый (балансируемый)
-
Полностью покрывающий (полный) индекс
-
Частичный (partial) индекс
-
Инкрементный (Delta) индекс
-
Real-time индекс
-
Глобальный индекс
-
Сегментный индекс
-
Локальный индекс
-
-
Что такое полнотекстовый поиск?
-
Что такое транзакции?
Ответ
Транза́кция — группа последовательных операций с базой данных, которая представляет собой логическую единицу работы с данными. Транзакция может быть выполнена либо целиком и успешно (Commit), соблюдая целостность данных и независимо от параллельно идущих других транзакций, либо не выполнена вообще (Rollback), и тогда она не должна произвести никакого эффекта.
-
Расскажите об уровнях изолированности транзакции
Ответ
Уровень изолированности транзакций — условное значение, определяющее, в какой мере в результате выполнения логически параллельных транзакций в СУБД допускается получение несогласованных данных. Шкала уровней изолированности транзакций содержит ряд значений, проранжированных от наинизшего до наивысшего; более высокий уровень изолированности соответствует лучшей согласованности данных, но его использование может снижать количество физически параллельно выполняемых транзакций.
При параллельном выполнении транзакций возможны следующие проблемы:
-
потерянное обновление (англ. lost update)
-
«грязное» чтение (англ. dirty read)
-
неповторяющееся чтение (англ. non-repeatable read)
-
фантомное чтение (англ. phantom reads)
Под «уровнем изоляции транзакций» понимается степень обеспечиваемой внутренними механизмами СУБД (то есть не требующей специального программирования) защиты от всех или некоторых видов вышеперечисленных несогласованности данных, возникающих при параллельном выполнении транзакций.
Первый из них является самым слабым, последний — самым сильным, каждый последующий включает в себя все предыдущие.
- Read uncommitted (чтение незафиксированных данных)
- Read committed (чтение фиксированных данных)
- Repeatable read (повторяемость чтения)
- Serializable (упорядочиваемость)
https://ru.wikipedia.org/wiki/Уровень_изолированности_транзакций
-
-
Что такое блокировочные и версионные СУБД?
-
Что такое репликация, для чего нужна?
Ответ
Репликация — одна из техник масштабирования баз данных. Состоит эта техника в том, что данные с одного сервера базы данных постоянно копируются (реплицируются) на один или несколько других (называемые репликами). Для приложения появляется возможность использовать не один сервер для обработки всех запросов, а несколько. Таким образом появляется возможность распределить нагрузку с одного сервера на несколько.
Существует два основных подхода при работе с репликацией данных:
- Репликация Master-Slave;
- Репликация Master-Master.
-
Что такое шардинг (партиционирование)?
Ответ
Шардинг (иногда шардирование) — это другая техника масштабирования работы с данными. Суть его в разделении (партиционирование) базы данных на отдельные части так, чтобы каждую из них можно было вынести на отдельный сервер. Этот процесс зависит от структуры Вашей базы данных и выполняется прямо в приложении в отличие от репликации:
Вертикальный шардинг
Вертикальный шардинг — это выделение таблицы или группы таблиц на отдельный сервер.
Горизонтальный шардинг
Горизонтальный шардинг — это разделение одной таблицы на разные сервера. Это необходимо использовать для огромных таблиц, которые не умещаются на одном сервере.
https://ruhighload.com/Шардинг+и+репликация
-
Типичные bottle necks?
-
Объяснить разницу между SQL Injection and CSS Injection?
-
Что такое BETWEEN?
-
Чем Like отличается от Ilike?
-
Чем Having отличается от Where?
-
Что такое нормализация и денормализация базы данных?
Ответ
Нормализация — процесс преобразования отношений базы данных к виду, отвечающему нормальным формам.Нормальные формы — это рекомендации по проектированию баз данных.
Для нормализации необходимо упорядочить данные в группы и найти логические связи между этими группами данных.
Денормализация — намеренное приведение структуры базы данных в состояние, не соответствующее критериям нормализации, обычно проводимое с целью ускорения операций чтения из базы за счет добавления избыточных данных.
https://oracle-patches.com/db/3632-нормализация-и-денормализация-базы-данных-нормальные-формы
-
Основная причина, по которой Redis работает быстрее PostgreSQL?
Ответ
Причина в месте хранения данных. В Redis данные хранятся в оперативной памяти, в PostgreSQL на жёстком диске.
Где искать ответы:
- https://www.pgexercises.com — тренажер для написания запросов
- https://sqlzoo.net/
- https://sqlbolt.com/
- http://sql-tutorial.ru/sqlbook/ru
Вопросы:
-
pgBouncer — что это и зачем нужно?
Ответ
pgbouncer — это пул соединения для PostgreSQL. Любое приложение может подключаться к pgbouncer так, как будто это сервер PostgreSQL ,и pgbouncer будет создавать соединения к действующему серверу PostgreSQL или переиспользовать существующие соединения.
Главная цель pgbouncer это снизить потери производительности при создании новых соединений (новых процессов) к PostgreSQL.
pgbouncer поддерживает несколько типов создания новых соединений и переиспользования существующих соединений:
Пул сессий (Session pooling)
Пул транзакций. (Transaction pooling)
Пул операторов (Statement pooling)
-
Системы репликации, что это и зачем нужно?
-
PgQ (другие очереди)?
Ответ
PgQ — это еще одна система очередей, написаная skytools на базе PostgreSql. Если написать руками очередь на БД, то она будет работать медленно и создавать большую нагрузку. В PgQ удалось избежать этого за счет использования «особой PostgreSql магии». PgQ — транзакционная очередь, что гарантирует, что вы увидите каждой событией хотя бы один раз.
Особенностью PgQ является то, что события из нее достаются пачками (batch). Поэтому надо быть внимательным, чтобы не отреагировать на одно и то же событие несколько раз (например, если обработчик собыий аварийно завершился, перед выходом стоит все необработанные события отправить на повтор и закрыть пакет).
-
Что такое синхронные и асинхронные операции?
-
Как устроены индексы postgres?
Где искать ответы: