You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Copy file name to clipboardExpand all lines: README.md
+15-15
Original file line number
Diff line number
Diff line change
@@ -69,7 +69,7 @@ If Python is installed, you'll see the version number; otherwise, you'll get an
69
69
70
70
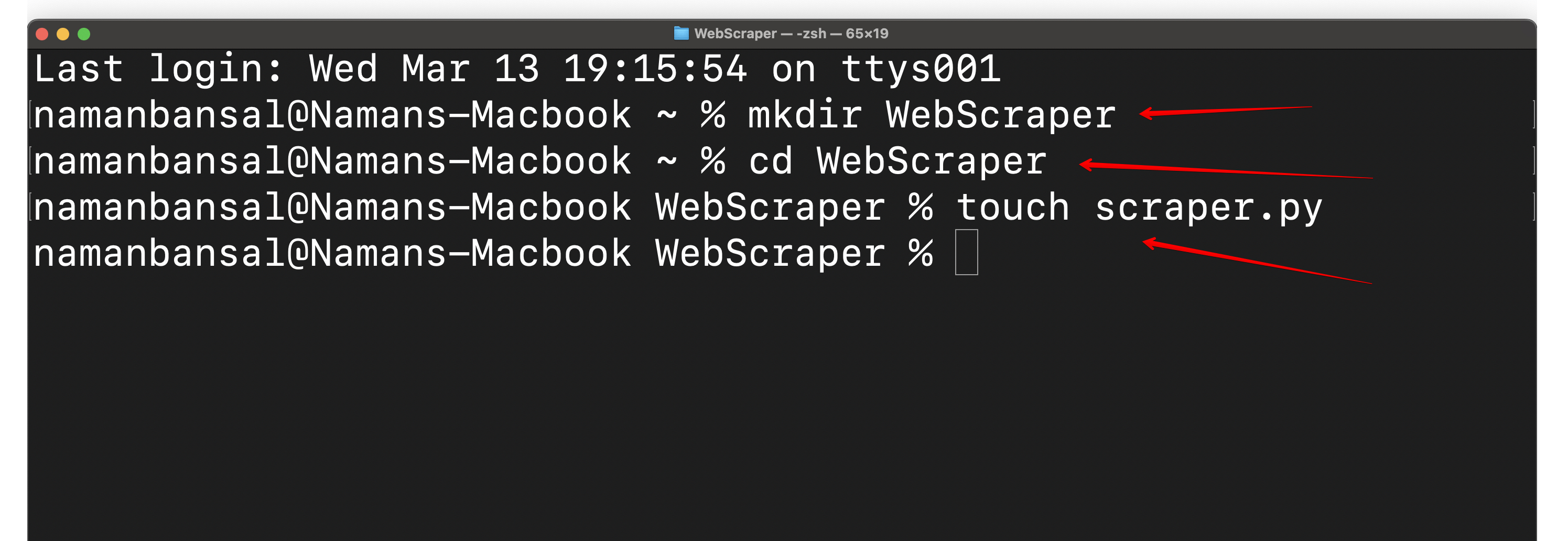
Next, create a folder named `WebScraper` and inside it create a file called `scraper.py`. Open this file in your preferred integrated development environment (IDE). We'll use [Visual Studio Code](https://code.visualstudio.com/) in this guide:
71
71
72
-
72
+

73
73
74
74
An IDE is a comprehensive tool that enables developers to write code, debug, test programs, create automations, and more. You'll use it to develop your HTML scraper.
With your virtual environment active, install a web scraping library. Options include [Playwright](https://playwright.dev/), [Selenium](https://www.selenium.dev/), [Beautiful Soup](https://www.crummy.com/software/BeautifulSoup/), and [Scrapy](https://scrapy.org/). For this tutorial, we'll use [Playwright](https://playwright.dev/python/docs/intro) because it's user-friendly, supports multiple browsers, handles dynamic content, and offers headless mode (scraping without a GUI).
116
116
@@ -202,33 +202,33 @@ main()
202
202
203
203
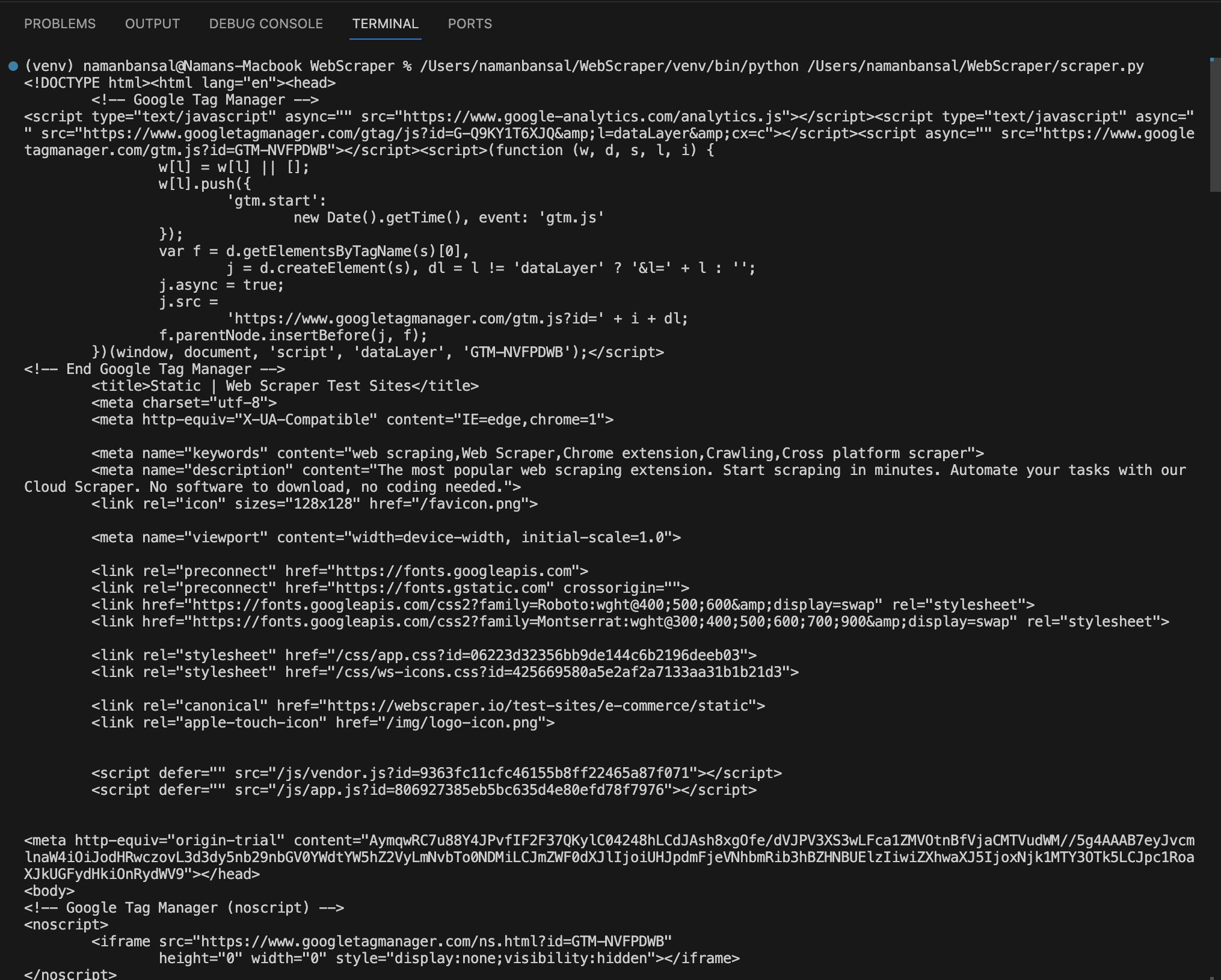
In Visual Studio Code, the extracted HTML appears like this:
204
204
205
-
205
+

206
206
207
207
## Targeting Specific HTML Elements
208
208
209
209
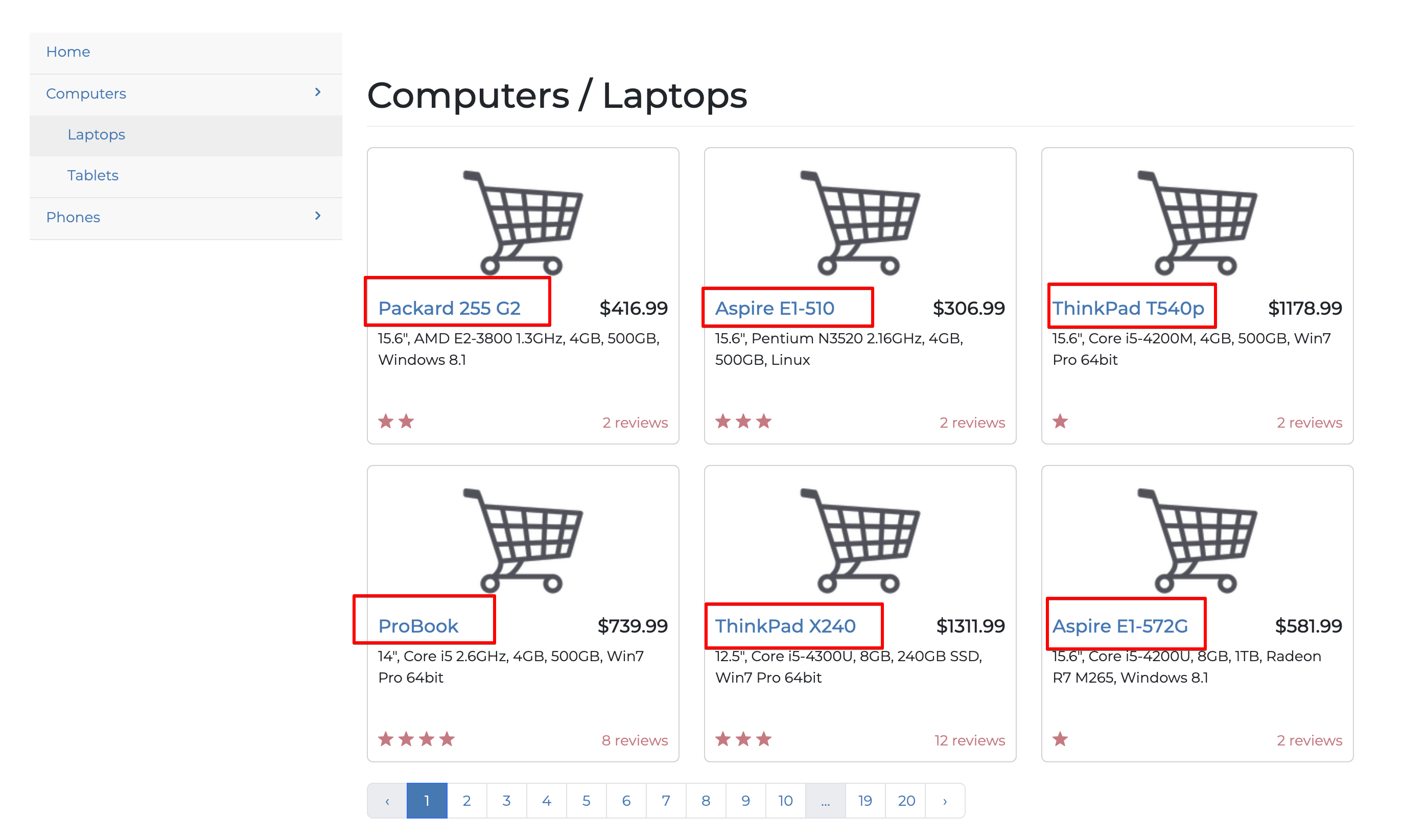
While extracting an entire webpage is possible, web scraping becomes truly valuable when you focus on specific information. In this section, we'll extract only the laptop titles from the website's first page:
210
210
211
-
211
+

212
212
213
213
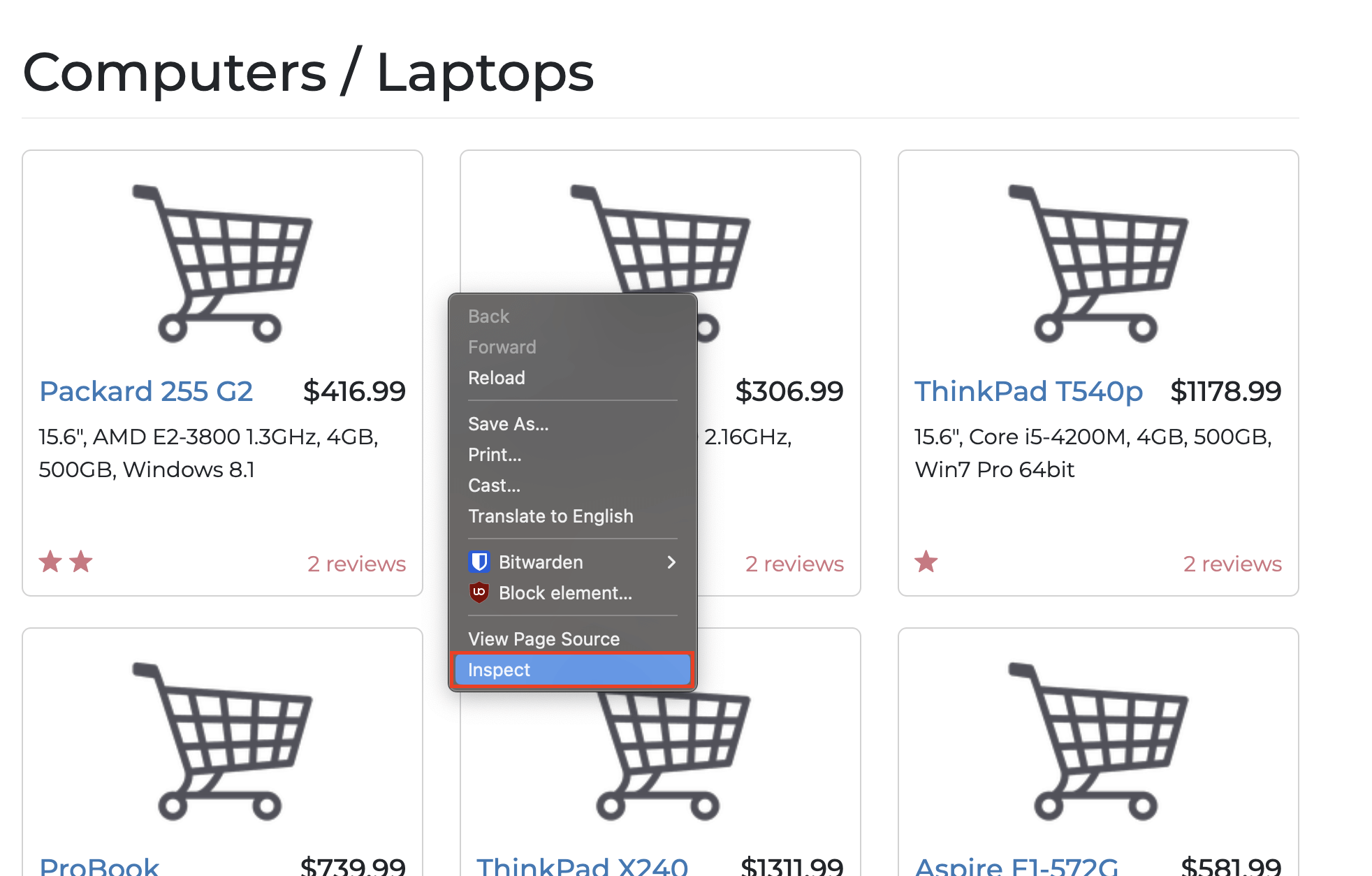
To extract specific elements, understand the website's structure first. Right-click and select **Inspect** on the page:
214
214
215
-
215
+

216
216
217
217
Alternatively, use these keyboard shortcuts:
218
218
- macOS: **Cmd + Option + I**
219
219
- Windows: **Control + Shift + C**
220
220
221
221
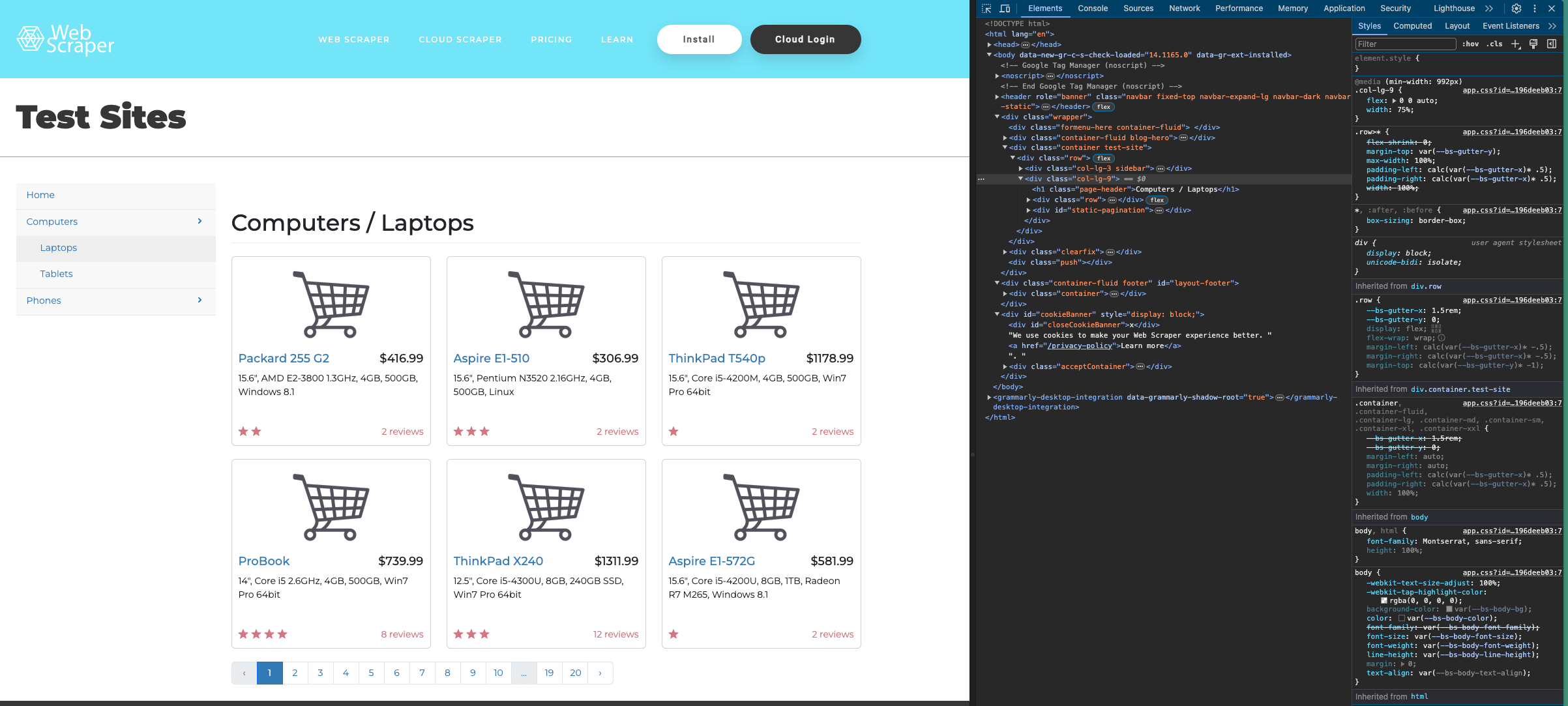
Here's the structure of our target page:
222
222
223
-
223
+

224
224
225
225
You can examine specific page elements using the selection tool in the top-left corner of the **Inspect** window:
226
226
227
-

227
+

228
228
229
229
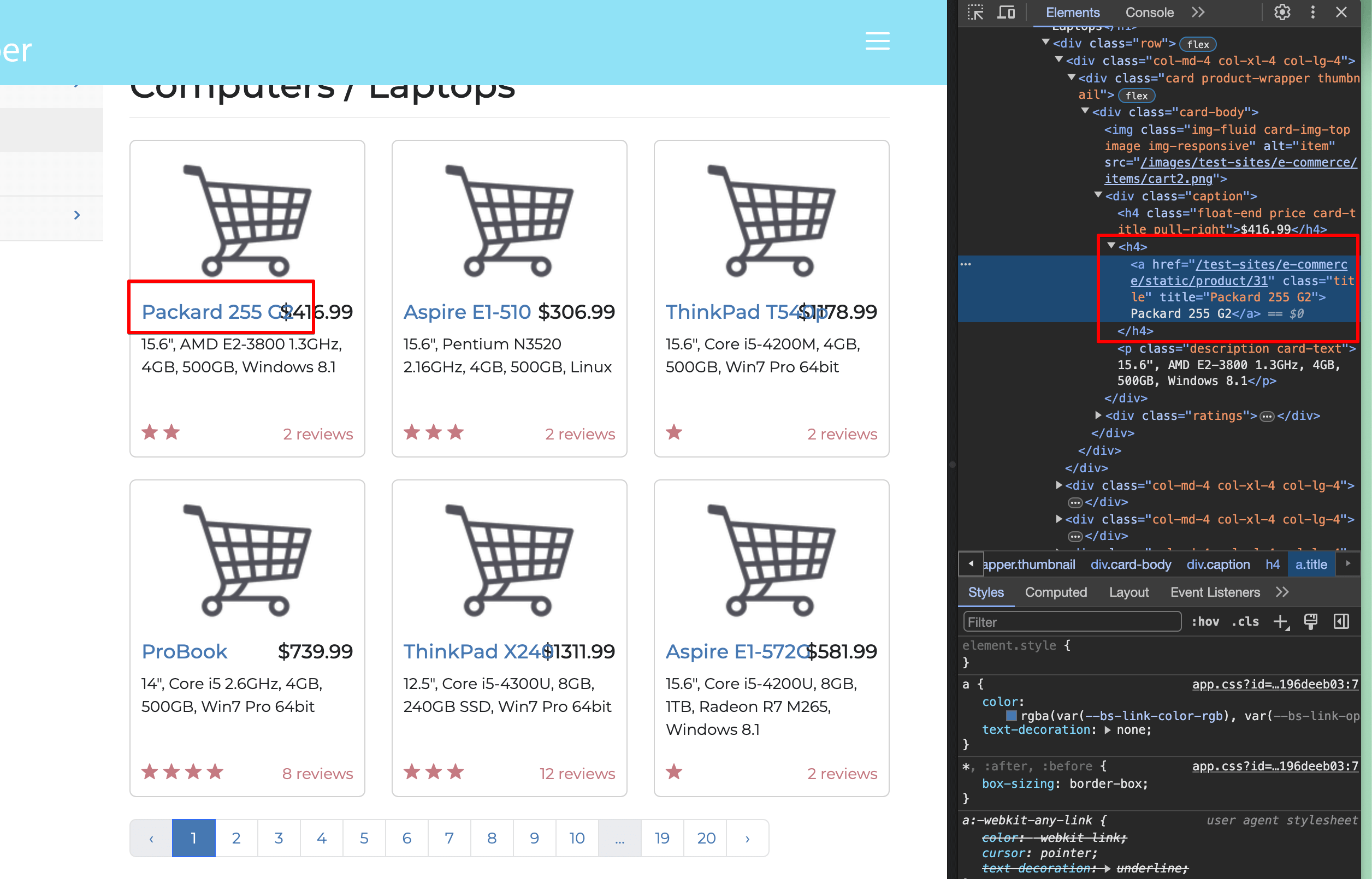
Select one of the laptop titles in the **Inspect** window:
230
230
231
-
231
+

232
232
233
233
You can see that each title is contained in an `<a> </a>` tag, wrapped by an `h4` tag, with the link having a `title` class. So we need to look for `<a href>` tags inside `<h4>` tags with a `title` class.
234
234
@@ -275,7 +275,7 @@ print(titles)
275
275
276
276
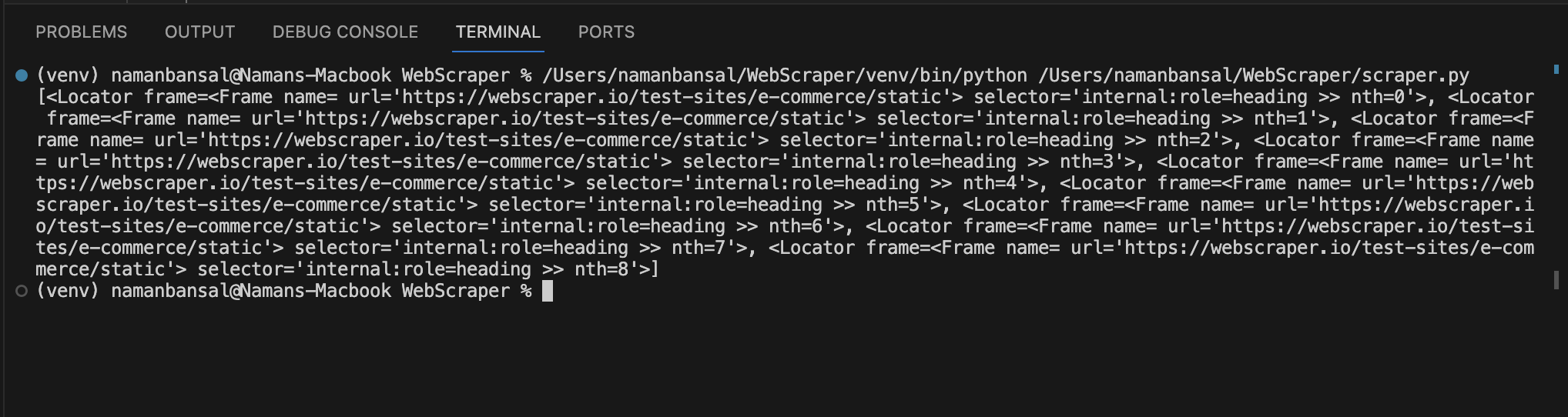
The output shows an array of elements:
277
277
278
-
278
+

279
279
280
280
This output doesn't show the titles directly, but references elements matching our criteria. We need to loop through these elements to find `<a>` tags with a `title` class and extract their text.
281
281
@@ -288,7 +288,7 @@ for title in titles:
288
288
289
289
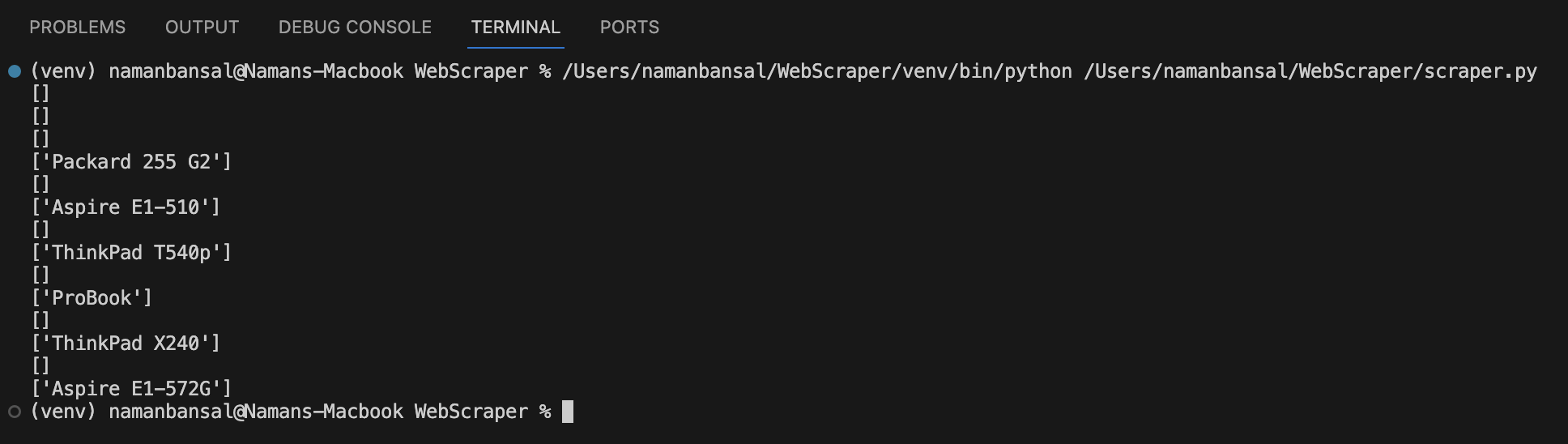
Running this code produces output like:
290
290
291
-
291
+

292
292
293
293
To filter out empty arrays, add:
294
294
@@ -332,7 +332,7 @@ Since we already know how to extract titles, we just need to learn how to naviga
332
332
333
333
The website has pagination buttons at the bottom. We need to locate and click on the "2" button programmatically. Inspecting the page reveals that this element is a list item (`<li>` tag) with the text "2":
334
334
335
-
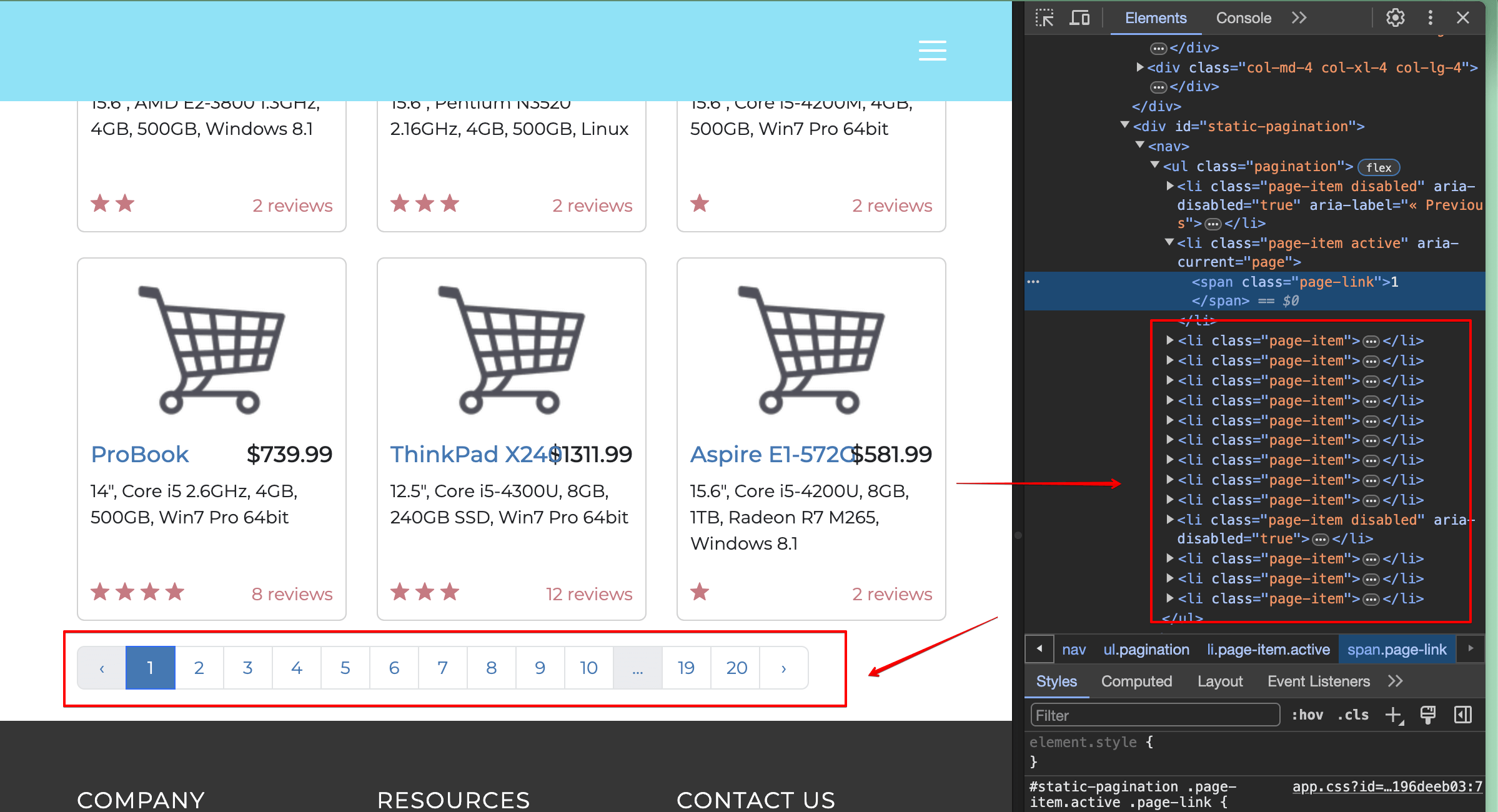
335
+

336
336
337
337
We can use the `get_by_role()` selector to find a list item and the `get_by_text()` selector to find text containing "2":
338
338
@@ -531,10 +531,10 @@ main()
531
531
532
532
After running this code, your CSV file should look like:
While this guide demonstrates basic web scraping, real-world scenarios often present challenges such as CAPTCHAs, rate limits, site layout changes, and regulatory requirements. Bright Data offers [solutions](https://brightdata.com/products) for these challenges, including advanced residential proxies to improve scraping performance, a Web Scraper IDE for building scalable scrapers, and a Web Unblocker to access blocked sites.
538
+
While this guide demonstrates basic web scraping, [real-world scenarios](https://brightdata.com/use-cases) often present challenges such as CAPTCHAs, rate limits, site layout changes, and regulatory requirements. Bright Data offers [solutions](https://brightdata.com/products) for these challenges, including [advanced residential proxies](https://brightdata.com/proxy-types/residential-proxies) to improve scraping performance, a Web Scraper IDE for building scalable scrapers, and a [Web Unblocker](https://brightdata.com/products/web-unlocker) to access blocked sites.
0 commit comments