items is 20%~30% slower than iteration via an index
#14421
Comments
|
I have implemented |
|
note; with |
This supports that |
|
Fwiw I am using |
|
Can compiler optimizing it automaticly? if developer not intend to mutate data they may not choose to using |
|
@bung87 that's what lent annotations should help with :) |
|
see #14447 which implements that; only 1 test failing (zero-functional); help welcome (see #14447 (comment)) |
Uh oh!
There was an error while loading. Please reload this page.
The items iterator for sequence is very slow compared to iterating via index.
This is particularly visible on objects that are around 1 cache-line (64 byte) (probably because they flush the items that were prefetched during the iteration.
Benchmark on my machine, repeated 5 times via a bash for loop
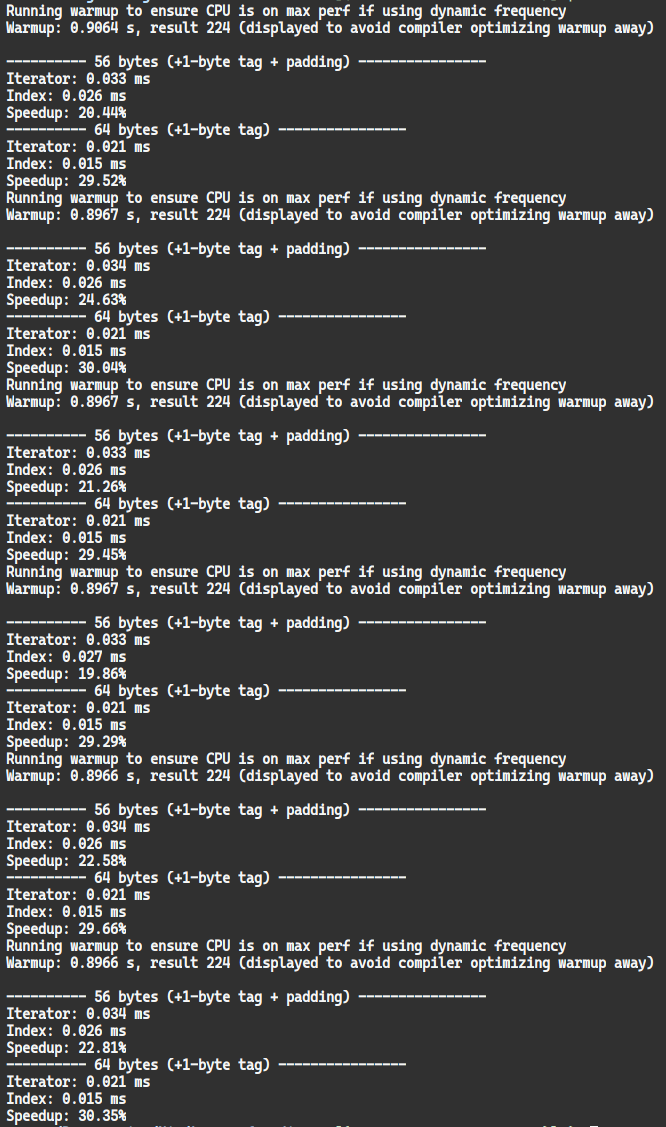
Looking into the generated C code (with -d:danger) this is due to an extra assignment:
Recommendation
The iterator should return
lentwhich is dependent on #14420The text was updated successfully, but these errors were encountered: