| ML.NET version | API type | Status | App Type | Data type | Scenario | ML Task | Algorithms |
|---|---|---|---|---|---|---|---|
| Microsoft.ML.Dnn 0.16.0-preview2 | Dynamic API | Up-to-date | Console app | Image files | Image classification | Image classification with TensorFlow model retrain based on transfer learning | InceptionV3 or ResNet |
Image classification is a common problem within the Deep Learning subject. This sample shows how to create your own custom image classifier by training your model based on the transfer learning approach which is basically retraining a pre-trained model (architecture such as InceptionV3 or ResNet) so you get a custom model trained on your own images.
In this sample app you create your own custom image classifier model by natively training a TensorFlow model from ML.NET API with your own images.
Image classifier scenario – Train your own custom deep learning model with ML.NET
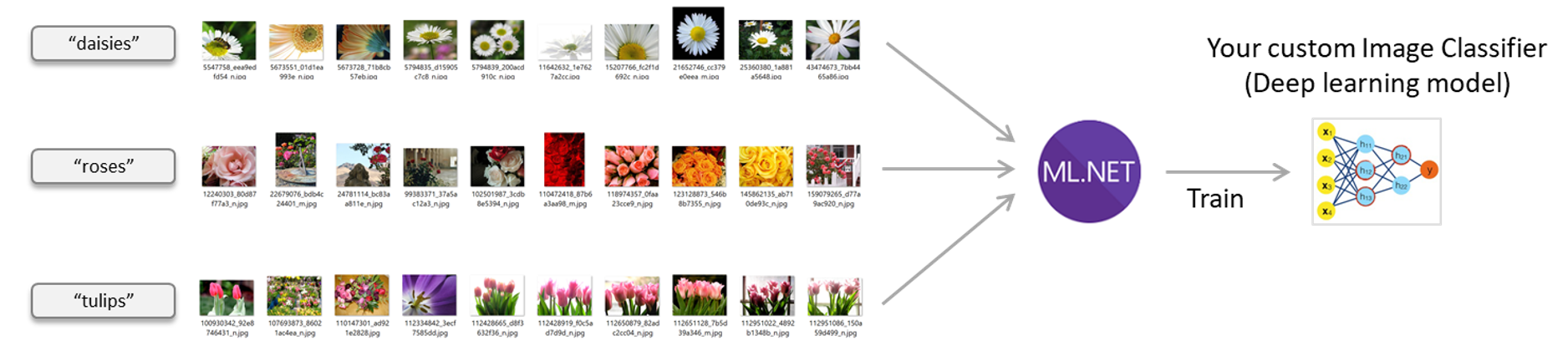
Image set license
This sample's dataset is based on the 'flower_photos imageset' available from Tensorflow at this URL. All images in this archive are licensed under the Creative Commons By-Attribution License, available at: https://creativecommons.org/licenses/by/2.0/
The full license information is provided in the LICENSE.txt file which is included as part of the same image set downloaded as a .zip file.
The by default imageset being downloaded by the sample has 200 images evenly distributed across 5 flower classes:
Images --> flower_photos_small_set -->
|
daisy
|
dandelion
|
roses
|
sunflowers
|
tulips
The name of each sub-folder is important because that'll be the name of each class/label the model is going to use to classify the images.
To solve this problem, first we will build an ML model. Then we will train the model on existing data, evaluate how good it is, and lastly we'll consume the model to classify a new image.

Building the model includes the following steps:
- Loading the image files (file paths in this case) into an IDataView
- Image classification using the ImageClassification estimator (high level API)
Define the schema of data in a class type and refer that type while loading data. Here the data class type in this sample.
public class ImageData
{
[LoadColumn(0)]
public string ImagePath;
[LoadColumn(1)]
public string Label;
}Since the API uses in-memory images so later on you'll be able to score the model with in-memory images, you need to define a class containing the image's bits in the type byte[] Image, like the following:
public class InMemoryImageData
{
public byte[] Image;
public string Label;
public string ImageFileName;
}Download the imageset and load its information by using the LoadImagesFromDirectory() and LoadFromEnumerable().
// 1. Download the image set and unzip
string finalImagesFolderName = DownloadImageSet(imagesDownloadFolderPath);
string fullImagesetFolderPath = Path.Combine(imagesDownloadFolderPath, finalImagesFolderName);
MLContext mlContext = new MLContext(seed: 1);
// 2. Load the initial full image-set into an IDataView and shuffle so it'll be better balanced
IEnumerable<ImageData> images = LoadImagesFromDirectory(folder: fullImagesetFolderPath, useFolderNameasLabel: true);
IDataView fullImagesDataset = mlContext.Data.LoadFromEnumerable(images);
IDataView shuffledFullImageFilePathsDataset = mlContext.Data.ShuffleRows(fullImagesDataset);Once it's loaded into the IDataView, the rows are shuffled so the dataset is better balanced before spliting into the training/test datasets.
Now, this step is very important. Since we want the ML model to work with in-memory images, we need to load the images into the dataset and actually do it by calling fit() and transform(). This step needs to be done in a initial and seggregated pipeline in the first place so the filepaths won't be used by the pipeline and model to create when training.
// 3. Load Images with in-memory type within the IDataView and Transform Labels to Keys (Categorical)
IDataView shuffledFullImagesDataset = mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "LabelAsKey",
inputColumnName: "Label",
keyOrdinality: ValueToKeyMappingEstimator.KeyOrdinality.ByValue)
.Append(mlContext.Transforms.LoadImages(outputColumnName: "Image",
imageFolder: fullImagesetFolderPath,
useImageType: false,
inputColumnName: "ImagePath"))
.Fit(shuffledFullImageFilePathsDataset)
.Transform(shuffledFullImageFilePathsDataset);In addition we also transformed the Labels to Keys (Categorical) before splitting the dataset. This is also important to do it before splitting if you don't want to deal/match the KeyOrdinality if transforming the labels in a second pipeline (the training pipeline).
Now, let's split the dataset in two datasets, one for training and the second for testing/validating the quality of the mode.
// 4. Split the data 80:20 into train and test sets, train and evaluate.
TrainTestData trainTestData = mlContext.Data.TrainTestSplit(shuffledFullImagesDataset, testFraction: 0.2);
IDataView trainDataView = trainTestData.TrainSet;
IDataView testDataView = trainTestData.TestSet;As the most important step, you define the model's training pipeline where you can see how easily you can train a new TensorFlow model which under the covers is based on transfer learning from a selected architecture (pre-trained model) such as Inception v3 or Resnet.
// 5. Define the model's training pipeline
var pipeline = mlContext.Model.ImageClassification(featuresColumnName:"Image", labelColumnName:"LabelAsKey",
arch: ImageClassificationEstimator.Architecture.InceptionV3, // Just by changing/selecting InceptionV3 here instead of ResnetV2101 you can try a different architecture/pre-trained model.
epoch: 100, //An epoch is one learning cycle where the learner sees the whole training data set.
batchSize: 10, //BatchSize sets the number of images to feed the model at a time.
learningRate: 0.01f,
metricsCallback: (metrics) => Console.WriteLine(metrics),
validationSet: testDataView
)
.Append(mlContext.Transforms.Conversion.MapKeyToValue(outputColumnName: "PredictedLabel", inputColumnName: "PredictedLabel"));The important line in the above code is the one using the mlContext.Model.ImageClassification classifier trainer which as you can see is a high level API where you just need to select the base pre-trained model to derive from, in this case Inception v3, but you can also select other pre-trained models such as Resnet v2101.
Those pre-trained models or architectures are the culmination of many ideas developed by multiple researchers over the years and you can easily take advantage of it now.
It is that simple, you don't even need to make image transformations (resize, normalizations, etc.). Depending on the selected architecture, the framework is doing the required image transformations under the covers so you simply need to use that single API.
In order to begin the training process you run Fit on the built pipeline:
// 4. Train/create the ML model
ITransformer trainedModel = pipeline.Fit(trainDataView);After the training, we evaluate the model's quality by using the test dataset.
The Evaluate function needs an IDataView with the predictions generated from the test dataset by calling Transfor().
// 5. Get the quality metrics (accuracy, etc.)
IDataView predictionsDataView = trainedModel.Transform(testDataset);
var metrics = mlContext.MulticlassClassification.Evaluate(predictionsDataView, labelColumnName:"LabelAsKey", predictedLabelColumnName: "PredictedLabel");
ConsoleHelper.PrintMultiClassClassificationMetrics("TensorFlow DNN Transfer Learning", metrics);Finally, you save the model:
// Save the model to assets/outputs (You get ML.NET .zip model file and TensorFlow .pb model file)
mlContext.Model.Save(trainedModel, trainDataView.Schema, outputMlNetModelFilePath);You should proceed as follows in order to train a model your model:
- Set
ImageClassification.Trainas starting project in Visual Studio - Press F5 in Visual Studio. After some seconds, the process will finish and you should have a new ML.NET model saved as the file
assets/outputs/imageClassifier.zip
In the sample's solution there's a second project named ImageClassifcation.Predict. That console app is simply loading your custom trained ML.NET model and performing a few sample predictions the same way a hypothetical end-user app could do.
First thing to do is to copy/paste the generated assets/outputs/imageClassifier.zip file into the inputs/MLNETModel folder of the consumption project.
In regards the code, you first need to load the model created during model training app execution.
MLContext mlContext = new MLContext(seed: 1);
ITransformer loadedModel = mlContext.Model.Load(imageClassifierModelZipFilePath, out var modelInputSchema);Then, your create a predictor engine object and finally make a few sample predictions by using the first image of the folder assets/inputs/images-for-predictions which has just a few images that were not used when training the model.
Note that now, when scoring, you only need the InMemoryImageData type which has the in-memory image.
That image could also be coming thorugh any other channel instead of loading it from a file.
For instance, the ImageClassification.WebApp in this same solution gets the image to use for the prediction through HTTP as an image provided by an end-user.
var predictionEngine = mlContext.Model.CreatePredictionEngine<InMemoryImageData, ImagePrediction>(loadedModel);
//Predict the first image in the folder
IEnumerable<InMemoryImageData> imagesToPredict = LoadInMemoryImagesFromDirectory(
imagesFolderPathForPredictions, false);
InMemoryImageData imageToPredict = new InMemoryImageData
{
Image = imagesToPredict.First().Image,
ImageFileName = imagesToPredict.First().ImageFileName
};
var prediction = predictionEngine.Predict(imageToPredict);
// Get the highest score and its index
float maxScore = prediction.Score.Max();
Console.WriteLine($"Image Filename : [{imageToPredict.ImageFileName}], " +
$"Predicted Label : [{prediction.PredictedLabel}], " +
$"Probability : [{maxScore}] "
);The prediction engine receives as parameter an object of type InMemoryImageData (containing 2 properties: Image and ImageFileName).
The ImageFileName is not used byt the model. You simple have it there so you can print the filename out out when showing the prediction. The prediction is only using the image's bits in the byte[] Image field.
Then the model returns and object of type ImagePrediction, which holds the PredictedLabel and all the Scores for all the classes/types of images.
Since the PredictedLabel is already a string it'll be shown in the console.
About the score for the predicted label, we just need to take the highest score which is the probability for the predicted label.
You should proceed as follows in order to train a model your model:
- Set
ImageClassification.Predictas starting project in Visual Studio - Press F5 in Visual Studio. After some seconds, the process will show you predictions by loading and using your custom
imageClassifier.zipmodel.
This sample app is retraining a TensorFlow model for image classification. As a user, you could think it is pretty similar to this other sample Image classifier using the TensorFlow Estimator featurizer. However, the internal implementation is very different under the covers. In that mentioned sample, it is using a 'model composition approach' where an initial TensorFlow model (i.e. InceptionV3 or ResNet) is only used to featurize the images and produce the binary information per image to be used by another ML.NET classifier trainer added on top (such as LbfgsMaximumEntropy). Therefore, even when that sample is using a TensorFlow model, you are training only with a ML.NET trainer, you don't retrain a new TensorFlow model but train an ML.NET model. That's why the output of that sample is only an ML.NET model (.zip file).
In contrast, this sample is natively retraining a new TensorFlow model based on a Transfer Learning approach but training a new TensorFlow model derived from the specified pre-trained model (Inception V3 or ResNet).
The important difference is that this approach is internally retraining with TensorFlow APIs and creating a new TensorFlow model (.pb). Then, the ML.NET .zip file model you use is just like a wrapper around the new retrained TensorFlow model. This is why you can also see a new .pb file generated after training:

In the screenshot below you can see how you can see that retrained TensorFlow model (custom_retrained_model_based_on_InceptionV3.meta.pb) in Netron, since it is a native TensorFlow model:

Benefits:
- Reuse across multiple frameworks and platforms: This ultimately means that since you natively trained a Tensorflow model, in addition to being able to run/consume that model with the ML.NET 'wrapper' model (.zip file), you could also take the .pb TensorFlow frozen model and run it on any other framework such as Python/Keras/TensorFlow, or a Java/Android app or any framework that supports TensorFlow.
- Flexibility and performace: Since ML.NET is internally retraining natively on Tensorflow layers, the ML.NET team will be able to optimize further and take multiple approaches like training on the last layer or training on multiple layers across the TensorFlow model and achive better quality levels.