DO NOT MERGE: Comparison of v1.10.2+RAI to v1.10.2
#212
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
…re in the sysimage (JuliaLang#52841) When triggers of extension are in the sysimage it is easy to end up with cycles in package loading. Say we have a package A with exts BExt and CExt and say that B and C is in the sysimage. - Upon loading A, we will immidiately start to precompile BExt (because the trigger B is "loaded" by virtue of being in the sysimage). - BExt will load A which will cause CExt to start precompiling (again because C is in the sysimage). - CExt will load A which will now cause BExt to start loading and we get a cycle. This is fixed in this PR by instead of looking at what modules are loaded, we look at what modules are actually `require`d and only use that to drive the loading of extensions. Fixes JuliaLang#52132. (cherry picked from commit 08d229f)
# Conflicts: # VERSION # Conflicts: # VERSION # Conflicts: # VERSION # Conflicts: # VERSION # Conflicts: # VERSION # Conflicts: # VERSION
This needed updating for 1.10 (#102). * port pool stats to 1.10 * increment/decrement current_pg_count --------- Co-authored-by: K Pamnany <[email protected]>
Prepend `[signal (X) ]thread (Y) ` to each backtrace line that is displayed. Co-authored-by: Diogo Netto <[email protected]>
* Add GC metric `last_incremental_sweep` * Update gc.c * Update gc.c
Prevent transparent huge pages (THP) overallocating pysical memory. Co-authored-by: Adnan Alhomssi <[email protected]>
Pass the types to the allocator functions.
-------
Before this PR, we were missing the types for allocations in two cases:
1. allocations from codegen
2. allocations in `gc_managed_realloc_`
The second one is easy: those are always used for buffers, right?
For the first one: we extend the allocation functions called from
codegen, to take the type as a parameter, and set the tag there.
I kept the old interfaces around, since I think that they cannot be
removed due to supporting legacy code?
------
An example of the generated code:
```julia
%ptls_field6 = getelementptr inbounds {}**, {}*** %4, i64 2
%13 = bitcast {}*** %ptls_field6 to i8**
%ptls_load78 = load i8*, i8** %13, align 8
%box = call noalias nonnull dereferenceable(32) {}* @ijl_gc_pool_alloc_typed(i8* %ptls_load78, i32 1184, i32 32, i64 4366152144) #7
```
Fixes JuliaLang#43688.
Fixes JuliaLang#45268.
Co-authored-by: Valentin Churavy <[email protected]>
…pings and tasks in application (JuliaLang#51301)
Sweeping of object pools will either construct a free list through dead objects (if there is at least one live object in a given page) or return the page to the OS (if there are no live objects whatsoever). With this PR, we're basically constructing the free-lists for each GC page in parallel.
GC threads don't have tasks associated with them.
Presence is controlled by a build-time option. Start a separate thread which simply sleeps. When heartbeats are enabled, this thread wakes up at specified intervals to verify that user code is heartbeating as requested and if not, prints task backtraces. Also fixes the call to `maxthreadid` in `generate_precompile.jl`.
When enabling heartbeats, the user must specify: - heartbeat_s: jl_heartbeat() must be called at least once every heartbeat_s; if it isn't, a one-line heartbeat loss report is printed - show_tasks_after_n: after these many heartbeat_s have passed without jl_heartbeat() being called, print task backtraces and stop all reporting - reset_after_n: after these many heartbeat_s have passed with jl_heartbeat() being called, print a heartbeats recovered message and reset reporting
`pool_live_bytes` was previously lazily updated during the GC, meaning it was only accurate right after a GC. Make this metric accurate if gathered after a GC has happened.
Otherwise we may just observe `gc_n_threads = 0` (`jl_gc_collect` sets it to 0 in the very end of its body) and this function becomes a no-op.
…uliaLang#52164) One of the limitations is that it's only accurate right after the GC. Still might be helpful for observability purposes.
We're suffering from heavy fragmentation in some of our workloads. Add a build-time option to enable 4k pages (instead of 16k) in the GC, since that improves memory utilization considerably for us. Drawback is that this may increase the number of `madvise` system calls in the sweeping phase by a factor of 4, but concurrent page sweeping should help with some of that.
…uliaLang#52943) **EDIT**: fixes JuliaLang#52937 by decreasing the contention on the page lists and only waking GC threads up if we have a sufficiently large number of pages. Seems to address the regression from the MWE of JuliaLang#52937: - master: ``` ../julia-master/julia --project=. run_benchmarks.jl serial obj_arrays issue-52937 -n5 --gcthreads=1 bench = "issue-52937.jl" ┌─────────┬────────────┬─────────┬───────────┬────────────┬──────────────┬───────────────────┬──────────┬────────────┐ │ │ total time │ gc time │ mark time │ sweep time │ max GC pause │ time to safepoint │ max heap │ percent gc │ │ │ ms │ ms │ ms │ ms │ ms │ us │ MB │ % │ ├─────────┼────────────┼─────────┼───────────┼────────────┼──────────────┼───────────────────┼──────────┼────────────┤ │ minimum │ 24841 │ 818 │ 78 │ 740 │ 44 │ 10088 │ 96 │ 3 │ │ median │ 24881 │ 834 │ 83 │ 751 │ 45 │ 10738 │ 97 │ 3 │ │ maximum │ 25002 │ 891 │ 87 │ 803 │ 48 │ 11074 │ 112 │ 4 │ │ stdev │ 78 │ 29 │ 4 │ 26 │ 1 │ 393 │ 7 │ 0 │ └─────────┴────────────┴─────────┴───────────┴────────────┴──────────────┴───────────────────┴──────────┴────────────┘ ../julia-master/julia --project=. run_benchmarks.jl serial obj_arrays issue-52937 -n5 --gcthreads=8 bench = "issue-52937.jl" ┌─────────┬────────────┬─────────┬───────────┬────────────┬──────────────┬───────────────────┬──────────┬────────────┐ │ │ total time │ gc time │ mark time │ sweep time │ max GC pause │ time to safepoint │ max heap │ percent gc │ │ │ ms │ ms │ ms │ ms │ ms │ us │ MB │ % │ ├─────────┼────────────┼─────────┼───────────┼────────────┼──────────────┼───────────────────┼──────────┼────────────┤ │ minimum │ 29113 │ 5200 │ 68 │ 5130 │ 12 │ 9724 │ 95 │ 18 │ │ median │ 29354 │ 5274 │ 69 │ 5204 │ 12 │ 10456 │ 96 │ 18 │ │ maximum │ 29472 │ 5333 │ 70 │ 5264 │ 14 │ 11913 │ 97 │ 18 │ │ stdev │ 138 │ 54 │ 1 │ 55 │ 1 │ 937 │ 1 │ 0 │ └─────────┴────────────┴─────────┴───────────┴────────────┴──────────────┴───────────────────┴──────────┴────────────┘ ``` - PR: ``` ../julia-master/julia --project=. run_benchmarks.jl serial obj_arrays issue-52937 -n5 --gcthreads=1 bench = "issue-52937.jl" ┌─────────┬────────────┬─────────┬───────────┬────────────┬──────────────┬───────────────────┬──────────┬────────────┐ │ │ total time │ gc time │ mark time │ sweep time │ max GC pause │ time to safepoint │ max heap │ percent gc │ │ │ ms │ ms │ ms │ ms │ ms │ us │ MB │ % │ ├─────────┼────────────┼─────────┼───────────┼────────────┼──────────────┼───────────────────┼──────────┼────────────┤ │ minimum │ 24475 │ 761 │ 77 │ 681 │ 40 │ 9499 │ 94 │ 3 │ │ median │ 24845 │ 775 │ 80 │ 698 │ 43 │ 10793 │ 97 │ 3 │ │ maximum │ 25128 │ 811 │ 85 │ 726 │ 47 │ 12820 │ 113 │ 3 │ │ stdev │ 240 │ 22 │ 3 │ 21 │ 3 │ 1236 │ 8 │ 0 │ └─────────┴────────────┴─────────┴───────────┴────────────┴──────────────┴───────────────────┴──────────┴────────────┘ ../julia-master/julia --project=. run_benchmarks.jl serial obj_arrays issue-52937 -n5 --gcthreads=8 bench = "issue-52937.jl" ┌─────────┬────────────┬─────────┬───────────┬────────────┬──────────────┬───────────────────┬──────────┬────────────┐ │ │ total time │ gc time │ mark time │ sweep time │ max GC pause │ time to safepoint │ max heap │ percent gc │ │ │ ms │ ms │ ms │ ms │ ms │ us │ MB │ % │ ├─────────┼────────────┼─────────┼───────────┼────────────┼──────────────┼───────────────────┼──────────┼────────────┤ │ minimum │ 24709 │ 679 │ 70 │ 609 │ 11 │ 9981 │ 95 │ 3 │ │ median │ 24869 │ 702 │ 70 │ 631 │ 12 │ 10705 │ 96 │ 3 │ │ maximum │ 24911 │ 708 │ 72 │ 638 │ 13 │ 10820 │ 98 │ 3 │ │ stdev │ 79 │ 12 │ 1 │ 12 │ 1 │ 401 │ 1 │ 0 │ └─────────┴────────────┴─────────┴───────────┴────────────┴──────────────┴───────────────────┴──────────┴────────────┘ ``` Also, performance on `objarray.jl` (an example of benchmark in which sweeping parallelizes well with the current implementation) seems fine: - master: ``` ../julia-master/julia --project=. run_benchmarks.jl multithreaded bigarrays -n5 --gcthreads=1 bench = "objarray.jl" ┌─────────┬────────────┬─────────┬───────────┬────────────┬──────────────┬───────────────────┬──────────┬────────────┐ │ │ total time │ gc time │ mark time │ sweep time │ max GC pause │ time to safepoint │ max heap │ percent gc │ │ │ ms │ ms │ ms │ ms │ ms │ us │ MB │ % │ ├─────────┼────────────┼─────────┼───────────┼────────────┼──────────────┼───────────────────┼──────────┼────────────┤ │ minimum │ 19301 │ 10792 │ 7485 │ 3307 │ 1651 │ 196 │ 4519 │ 56 │ │ median │ 21415 │ 12646 │ 9094 │ 3551 │ 1985 │ 241 │ 6576 │ 59 │ │ maximum │ 21873 │ 13118 │ 9353 │ 3765 │ 2781 │ 330 │ 8793 │ 60 │ │ stdev │ 1009 │ 932 │ 757 │ 190 │ 449 │ 50 │ 1537 │ 2 │ └─────────┴────────────┴─────────┴───────────┴────────────┴──────────────┴───────────────────┴──────────┴────────────┘ ../julia-master/julia --project=. run_benchmarks.jl multithreaded bigarrays -n5 --gcthreads=8 bench = "objarray.jl" ┌─────────┬────────────┬─────────┬───────────┬────────────┬──────────────┬───────────────────┬──────────┬────────────┐ │ │ total time │ gc time │ mark time │ sweep time │ max GC pause │ time to safepoint │ max heap │ percent gc │ │ │ ms │ ms │ ms │ ms │ ms │ us │ MB │ % │ ├─────────┼────────────┼─────────┼───────────┼────────────┼──────────────┼───────────────────┼──────────┼────────────┤ │ minimum │ 13135 │ 4377 │ 3350 │ 1007 │ 491 │ 231 │ 6062 │ 33 │ │ median │ 13164 │ 4540 │ 3370 │ 1177 │ 669 │ 256 │ 6383 │ 35 │ │ maximum │ 13525 │ 4859 │ 3675 │ 1184 │ 748 │ 320 │ 7528 │ 36 │ │ stdev │ 183 │ 189 │ 146 │ 77 │ 129 │ 42 │ 584 │ 1 │ └─────────┴────────────┴─────────┴───────────┴────────────┴──────────────┴───────────────────┴──────────┴────────────┘ ``` - PR: ``` ../julia-master/julia --project=. run_benchmarks.jl multithreaded bigarrays -n5 --gcthreads=1 bench = "objarray.jl" ┌─────────┬────────────┬─────────┬───────────┬────────────┬──────────────┬───────────────────┬──────────┬────────────┐ │ │ total time │ gc time │ mark time │ sweep time │ max GC pause │ time to safepoint │ max heap │ percent gc │ │ │ ms │ ms │ ms │ ms │ ms │ us │ MB │ % │ ├─────────┼────────────┼─────────┼───────────┼────────────┼──────────────┼───────────────────┼──────────┼────────────┤ │ minimum │ 19642 │ 10931 │ 7566 │ 3365 │ 1653 │ 204 │ 5688 │ 56 │ │ median │ 21441 │ 12717 │ 8948 │ 3770 │ 1796 │ 217 │ 6972 │ 59 │ │ maximum │ 23494 │ 14643 │ 10576 │ 4067 │ 2513 │ 248 │ 8229 │ 62 │ │ stdev │ 1408 │ 1339 │ 1079 │ 267 │ 393 │ 19 │ 965 │ 2 │ └─────────┴────────────┴─────────┴───────────┴────────────┴──────────────┴───────────────────┴──────────┴────────────┘ ../julia-master/julia --project=. run_benchmarks.jl multithreaded bigarrays -n5 --gcthreads=8 bench = "objarray.jl" ┌─────────┬────────────┬─────────┬───────────┬────────────┬──────────────┬───────────────────┬──────────┬────────────┐ │ │ total time │ gc time │ mark time │ sweep time │ max GC pause │ time to safepoint │ max heap │ percent gc │ │ │ ms │ ms │ ms │ ms │ ms │ us │ MB │ % │ ├─────────┼────────────┼─────────┼───────────┼────────────┼──────────────┼───────────────────┼──────────┼────────────┤ │ minimum │ 13365 │ 4544 │ 3389 │ 1104 │ 516 │ 255 │ 6349 │ 34 │ │ median │ 13445 │ 4624 │ 3404 │ 1233 │ 578 │ 275 │ 6385 │ 34 │ │ maximum │ 14413 │ 5278 │ 3837 │ 1441 │ 753 │ 300 │ 7547 │ 37 │ │ stdev │ 442 │ 303 │ 194 │ 121 │ 89 │ 18 │ 522 │ 1 │ └─────────┴────────────┴─────────┴───────────┴────────────┴──────────────┴───────────────────┴──────────┴────────────┘ ```
This PR is to continue the work on the following PR: Prevent OOMs during heap snapshot: Change to streaming out the snapshot data (JuliaLang#51518 ) Here are the commit history: ``` * Streaming the heap snapshot! This should prevent the engine from OOMing while recording the snapshot! Now we just need to sample the files, either online, before downloading, or offline after downloading :) If we're gonna do it offline, we'll want to gzip the files before downloading them. * Allow custom filename; use original API * Support legacy heap snapshot interface. Add reassembly function. * Add tests * Apply suggestions from code review * Update src/gc-heap-snapshot.cpp * Change to always save the parts in the same directory This way you can always recover from an OOM * Fix bug in reassembler: from_node and to_node were in the wrong order * Fix correctness mistake: The edges have to be reordered according to the node order. That's the whole reason this is tricky. But i'm not sure now whether the SoAs approach is actually an optimization.... It seems like we should probably prefer to inline the Edges right into the vector, rather than having to do another random lookup into the edges table? * Debugging messed up edge array idxs * Disable log message * Write the .nodes and .edges as binary data * Remove unnecessary logging * fix merge issues * attempt to add back the orphan node checking logic ``` --------- Co-authored-by: Nathan Daly <[email protected]> Co-authored-by: Nathan Daly <[email protected]>
…53512) This is a partial back-port of JuliaLang#50924, where we discovered that the optimizer would ignore: 1. must-throw `%XX = SlotNumber(_)` statements 2. must-throw `goto #bb if not %x` statements This is mostly harmless, except that in the case of (1) we can accidentally fall through the statically deleted (`Const()`-wrapped) code from inference and end up observing a control-flow edge that never existed. If the spurious edge is to a catch block, then the edge is invalid semantically and breaks our SSA conversion. This one-line change fixes (1) but not (2), which is enough for IR validity. Resolves part of JuliaLang#53366. (cherry picked from commit 035d17a)
…liaLang#53553) typeintersect: fix `UnionAll` unaliasing bug caused by innervars. (cherry picked from commit 56f1c8a)
Instead of always updating it. This should speed up loading only method specializations.
…Lang#54634) (#199) This avoids a: `error: non-private labels cannot appear between .cfi_startproc / .cfi_endproc pairs` error. That error was introduced in https://reviews.llvm.org/D155245#4657075 see also llvm/llvm-project#72802 (cherry picked from commit a4e793e) (cherry picked from commit 3f35094) Co-authored-by: Gabriel Baraldi <[email protected]>
* Optionally disallow defining new methods and drop backedges
… counter -- per (module, method name) pair (JuliaLang#53719) (#179) As mentioned in JuliaLang#53716, we've been noticing that `precompile` statements lists from one version of our codebase often don't apply cleanly in a slightly different version. That's because a lot of nested and anonymous function names have a global numeric suffix which is incremented every time a new name is generated, and these numeric suffixes are not very stable across codebase changes. To solve this, this PR makes the numeric suffixes a bit more fine grained: every pair of (module, top-level/outermost function name) will have its own counter, which should make nested function names a bit more stable across different versions. This PR applies @JeffBezanson's idea of making the symbol name changes directly in `current-julia-module-counter`. Here is an example: ```Julia julia> function foo(x) function bar(y) return x + y end end foo (generic function with 1 method) julia> f = foo(42) (::var"#bar#foo##0"{Int64}) (generic function with 1 method) ``` Co-authored-by: Diogo Netto <[email protected]>
* Add per-task metrics (JuliaLang#56320) Close JuliaLang#47351 (builds on top of JuliaLang#48416) Adds two per-task metrics: - running time = amount of time the task was actually running (according to our scheduler). Note: currently inclusive of GC time, but would be good to be able to separate that out (in a future PR) - wall time = amount of time between the scheduler becoming aware of this task and the task entering a terminal state (i.e. done or failed). We record running time in `wait()`, where the scheduler stops running the task as well as in `yield(t)`, `yieldto(t)` and `throwto(t)`, which bypass the scheduler. Other places where a task stops running (for `Channel`, `ReentrantLock`, `Event`, `Timer` and `Semaphore` are all implemented in terms of `wait(Condition)`, which in turn calls `wait()`. `LibuvStream` similarly calls `wait()`. This should capture everything (albeit, slightly over-counting task CPU time by including any enqueuing work done before we hit `wait()`). The various metrics counters could be a separate inlined struct if we think that's a useful abstraction, but for now i've just put them directly in `jl_task_t`. They are all atomic, except the `metrics_enabled` flag itself (which we now have to check on task start/switch/done even if metrics are not enabled) which is set on task construction and marked `const` on the julia side. In future PRs we could add more per-task metrics, e.g. compilation time, GC time, allocations, potentially a wait-time breakdown (time waiting on locks, channels, in the scheduler run queue, etc.), potentially the number of yields. Perhaps in future there could be ways to enable this on a per-thread and per-task basis. And potentially in future these same timings could be used by `@time` (e.g. writing this same timing data to a ScopedValue like in JuliaLang#55103 but only for tasks lexically scoped to inside the `@time` block). Timings are off by default but can be turned on globally via starting Julia with `--task-metrics=yes` or calling `Base.Experimental.task_metrics(true)`. Metrics are collected for all tasks created when metrics are enabled. In other words, enabling/disabling timings via `Base.Experimental.task_metrics` does not affect existing `Task`s, only new `Task`s. The other new APIs are `Base.Experimental.task_running_time_ns(::Task)` and `Base.Experimental.task_wall_time_ns(::Task)` for retrieving the new metrics. These are safe to call on any task (including the current task, or a task running on another thread). All these are in `Base.Experimental` to give us room to change up the APIs as we add more metrics in future PRs (without worrying about release timelines). cc @NHDaly @kpamnany @d-netto --------- Co-authored-by: Pete Vilter <[email protected]> Co-authored-by: K Pamnany <[email protected]> Co-authored-by: Nathan Daly <[email protected]> Co-authored-by: Valentin Churavy <[email protected]> * Address review comments --------- Co-authored-by: Pete Vilter <[email protected]> Co-authored-by: K Pamnany <[email protected]> Co-authored-by: Nathan Daly <[email protected]> Co-authored-by: Valentin Churavy <[email protected]>
…uliaLang#56814) (#200) I propose a change in the implementation of the `ReentrantLock` to improve its overall throughput for short critical sections and fix the quadratic wake-up behavior where each unlock schedules **all** waiting tasks on the lock's wait queue. This implementation follows the same principles of the `Mutex` in the [parking_lot](https://github.com/Amanieu/parking_lot/tree/master) Rust crate which is based on the Webkit [WTF::ParkingLot](https://webkit.org/blog/6161/locking-in-webkit/) class. Only the basic working principle is implemented here, further improvements such as eventual fairness will be proposed separately. The gist of the change is that we add one extra state to the lock, essentially going from: ``` 0x0 => The lock is not locked 0x1 => The lock is locked by exactly one task. No other task is waiting for it. 0x2 => The lock is locked and some other task tried to lock but failed (conflict) ``` To: ``` ``` In the current implementation we must schedule all tasks to cause a conflict (state 0x2) because on unlock we only notify any task if the lock is in the conflict state. This behavior means that with high contention and a short critical section the tasks will be effectively spinning in the scheduler queue. With the extra state the proposed implementation has enough information to know if there are other tasks to be notified or not, which means we can always notify one task at a time while preserving the optimized path of not notifying if there are no tasks waiting. To improve throughput for short critical sections we also introduce a bounded amount of spinning before attempting to park. Not spinning on the scheduler queue greatly reduces the CPU utilization of the following example: ```julia function example() lock = ReentrantLock() @sync begin for i in 1:10000 Threads.@Spawn begin @lock lock begin sleep(0.001) end end end end end @time example() ``` Current: ``` 28.890623 seconds (101.65 k allocations: 7.646 MiB, 0.25% compilation time) ``` 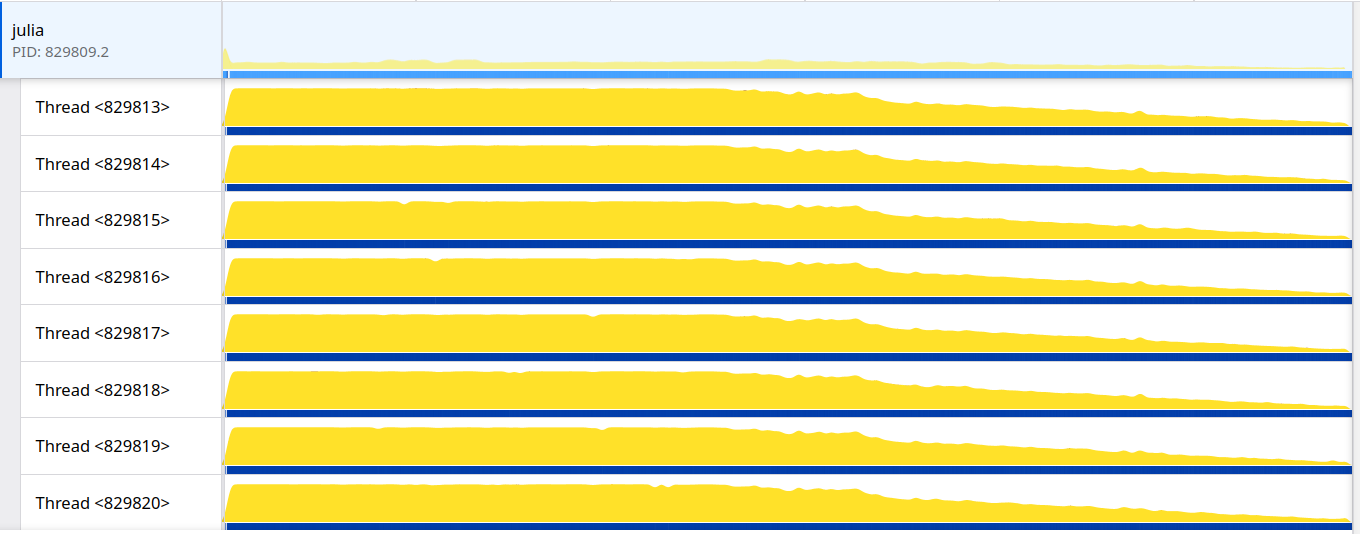 Proposed: ``` 22.806669 seconds (101.65 k allocations: 7.814 MiB, 0.35% compilation time) ```  In a micro-benchmark where 8 threads contend for a single lock with a very short critical section we see a ~2x improvement. Current: ``` 8-element Vector{Int64}: 6258688 5373952 6651904 6389760 6586368 3899392 5177344 5505024 Total iterations: 45842432 ``` Proposed: ``` 8-element Vector{Int64}: 12320768 12976128 10354688 12845056 7503872 13598720 13860864 11993088 Total iterations: 95453184 ``` ~~In the uncontended scenario the extra bookkeeping causes a 10% throughput reduction:~~ EDIT: I reverted _trylock to the simple case to recover the uncontended throughput and now both implementations are on the same ballpark (without hurting the above numbers). In the uncontended scenario: Current: ``` Total iterations: 236748800 ``` Proposed: ``` Total iterations: 237699072 ``` Closes JuliaLang#56182 Co-authored-by: André Guedes <[email protected]>
…JuliaLang#57004) (#204) Fixes JuliaLang#56889. Before this PR, an exception thrown while constructing the objects to log (the `msg`) would be caught and logged. However, an exception thrown while _printing_ the msg to an IO would _not_ be caught, and can abort the program. This breaks the promise that enabling verbose debug logging shouldn't introduce new crashes. After this PR, an exception thrown during handle_message is caught and logged, just like an exception during `msg` construction: ```julia julia> struct Foo end julia> Base.show(::IO, ::Foo) = error("oh no") julia> begin # Unexpectedly, the execption thrown while printing `Foo()` escapes @info Foo() # So we never reach this line! :'( println("~~~~~ ALL DONE ~~~~~~~~") end ┌ Error: Exception while generating log record in module Main at REPL[10]:3 │ exception = │ oh no │ Stacktrace: │ [1] error(s::String) │ @ Base ./error.jl:44 │ [2] show(::IOBuffer, ::Foo) │ @ Main ./REPL[9]:1 ... │ [30] repl_main │ @ ./client.jl:593 [inlined] │ [31] _start() │ @ Base ./client.jl:568 └ @ Main REPL[10]:3 ~~~~~ ALL DONE ~~~~~~~~ ``` This PR respects the change made in JuliaLang#36600 to keep the codegen as small as possible, by putting the new try/catch into a no-inlined function, so that we don't have to introduce a new try/catch in the macro-generated code body. --------- Co-authored-by: Jameson Nash <[email protected]>
--------- Co-authored-by: Jameson Nash <[email protected]> Co-authored-by: Nick Robinson <[email protected]>
…7045) (#208) This is still a work in progress, but it should help determine what a straggler thread was doing during the stop-the-world phase and why it failed to reach a safepoint in a timely manner. We've encountered long TTSP issues in production, and this tool should provide a valuable means to accurately diagnose them.
And not `==`.
v1.10.2+RAI to v1.10.2v1.10.2+RAI to v1.10.2
…215) Minor tweak to the error message: embed the exit code of the Julia child process that failed to compile the package.
* inference: avoid inferring unreachable code methods (JuliaLang#51317) (cherry picked from commit 0a82b71) * inference: ensure inferring reachable code methods (JuliaLang#57088) PR JuliaLang#51317 was a bit over-eager about inferring inferring unreachable code methods. Filter out the Vararg case, since that can be handled by simply removing it instead of discarding the whole call. Fixes JuliaLang#56628 (cherry picked from commit eb9f24c) --------- Co-authored-by: Jameson Nash <[email protected]>
…gler (JuliaLang#57579) In the line of C code: ```C const int64_t timeout = jl_options.timeout_for_safepoint_straggler_s * 1000000000; ``` `jl_options.timeout_for_safepoint_straggler_s` is an `int16_t` and `1000000000` is an `int32_t`. The result of `jl_options.timeout_for_safepoint_straggler_s * 1000000000` will be an `int32_t` which may not be large enough to hold the value of `jl_options.timeout_for_safepoint_straggler_s` after converting to nanoseconds, leading to overflow.
Co-authored-by: Gabriel Baraldi <[email protected]>
…ng#55915) (#226) Co-authored-by: Ian Butterworth <[email protected]>
This was resulting in it being too aggressive at filtering out "duplicate" results, resulting in possible inference mistakes or missing guardsig entries. Fixes: JuliaLang#50722 (comment) (cherry picked from commit 762801c) Co-authored-by: Jameson Nash <[email protected]>
* Use faster PRNG in the allocations profiler (JuliaLang#57761) `rand()` locks and is slow. This uses the seed from `ptls`. * Use correct arguments for 1.10's `cong()` Also remove a warning from array.c
This does not fix the underlying issue that can occur here which is a collision of build_ids.lo between modules in IR decompression. Fixing that requires a somewhat significant overhaul to the serialization of IR (probably using the module identity as a key). This does mean we use a lot more of the bits available here so it makes collisions a lot less likely( they were already extremely rare) but hrtime does tend to only use the lower bits of a 64 bit integer and this will hopefully add some more randomness and make this even less likely Co-authored-by: Gabriel Baraldi <[email protected]>
#235) Co-authored-by: gbaraldi <[email protected]>
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
No description provided.