raise exception after exiting watcher.each #214
Conversation
| @@ -119,6 +119,7 @@ def process_namespace_watcher_notices(watcher) | |||
| @stats.bump(:namespace_cache_watch_ignored) | |||
| end | |||
| end | |||
| raise | |||
There was a problem hiding this comment.
Won't this simply fall through all the time and raise an exception on every notification. Should we be evaluating for a specific notice.type or at least have continue statements above
There was a problem hiding this comment.
as i suspected:
Error: test: pod MODIFIED cached when hostname matches(DefaultPodWatchStrategyTest)
: RuntimeError:
/home/circleci/fluent-plugin-kubernetes_metadata_filter/lib/fluent/plugin/kubernetes_metadata_watch_pods.rb:128:in `process_pod_watcher_notices'
/home/circleci/fluen
There was a problem hiding this comment.
its probably something more like:
when 'ERROR':
message = notice['object']['message'] if notice['object'] && notice['object']['message']
raise "Error while watching namespaces: #{message}"
There was a problem hiding this comment.
I was thinking about doing it with when 'ERROR', but then it can still exit the watcher.each block without an exception which can cause endless loop without backoff.
I don't know how this testing framework works, but in reality it stays inside the watcher.each block until the connection is open. Watching opens long running connections, the API server usually kills the connection after 40-50 minutes.
There was a problem hiding this comment.
Hmm... I thought the notice.type value can only be one of these there: ADDED, MODIFIED, DELETED.
@jcantrill 's suggestion in https://github.com/fabric8io/fluent-plugin-kubernetes_metadata_filter/pull/214/files#r384729998 makes sense to me.
Looking at the issue reported at #213 (comment), it's not an unexpected exception. Besides, if an exception if thrown,
should have caught it.There was a problem hiding this comment.
There is no exception thrown when the connection is closed.
When you open the HTTP connection for the watcher you get a 200 OK reply from the server, but connection stays open and it is streaming the events over the same connection. Kubernetes will close it after around 1 hour (at least on our cluster).
Once it's closed there is no exception, it's finishing normally.
So the thread loop will execute, but because there were no exception the rescue block did not execute and nothing set the pod_watcher to nil. It will use resource_version from the first run.
Kubernetes API remembers old resources for a while, but after some time it will return ERROR with "too old resource version" message and closes the connection (no exception happens).
When this happens the thread loop will start the watcher again with the old resource version, gets error again and this continues in a loop. It results in a high load on the API server and no way to recover except restarting fluentd.
I can rework this PR to use the when 'ERROR' case, but then the issue can still happen if the connection is closed by the API server without returning ERROR and throwing exception.
I think an exception should be raised whenever the watcher.each block is exited, because it means the long-running connection was closed gracefully.
Unfortunately I am not sure how I can make it work with the tests.
There was a problem hiding this comment.
Re #214 (comment): Ah I see. That sounds good to me. Instead of a simple raise, can we give it some message to help with debugging / trouble shooting when the issue happens?
For the fact that it returned ERROR notice, seems like there is some discussion at kubeclient/pull/275. Sounds like it might be fixed in
|
Perhaps we can get this fix merged the way it is right now to handle the |
|
@qingling128 Iooking at the code again, I think Thread.current[:pod_watch_retry_count] should be reset when non-error events are received otherwise that counter will just keep increasing whenever the API server respons 410 Gone and after couple of iterations the code will raise Fluent::UnrecoverableError. What do you think? |
|
@mszabo - Good point. What do you think about resetting it to 0 in the |
|
@qingling128 sounds good. I tried to add it after the resourceVersion successfully queried from the API server, but it makes the "pod watch retries when exceptions are encountered" test hang forever and I am not sure how to fix the test |
|
@mszabo - Interesting. I took a closer look. This (https://github.com/fabric8io/fluent-plugin-kubernetes_metadata_filter/pull/215/files) seems to work and should be equivalent. Also, now I think about it, once an BTW, I'm not entirely sure why the test failed in the other approach. I guess it might be related to how the stubs work or something. |
|
@mszabo can you post unit test results until we can properly fix up the CI? |
|
I could view the test results in this PR. Quoted below: I was able to reproduce the error above locally. The tests simply hang indefinitely until I manually killed it. BTW, CI seems fixed already (at least it's passing for the |
@qingling128 I don't think #215 is equivalent. As you said, |
|
@qingling128 yes, it's recoverable, just need to refresh the resourceVersion. The commit you mentioned also could help the situation, but get_pods_and_start_watcher is a better place to reset the counter in my opinion. I think the test is wrong here. Anyway, I am also happy with 1382745 as well and the tests can stay as is with it. |
|
I removed the counter resets from this PR as it is handled in 1382745 |
|
FYI, I set up some experiments that ran overnight, and verified that the latest commit (which includes this fix) has better performance than The two commit hashes of the branches in comparison Commit hash of Commit hash of CPU comparison Memory comparison Fluentd log entry processing capability comparison Retries still works No container restarts Thanks @mszabo and @jcantrill ! One thing I noticed is that |
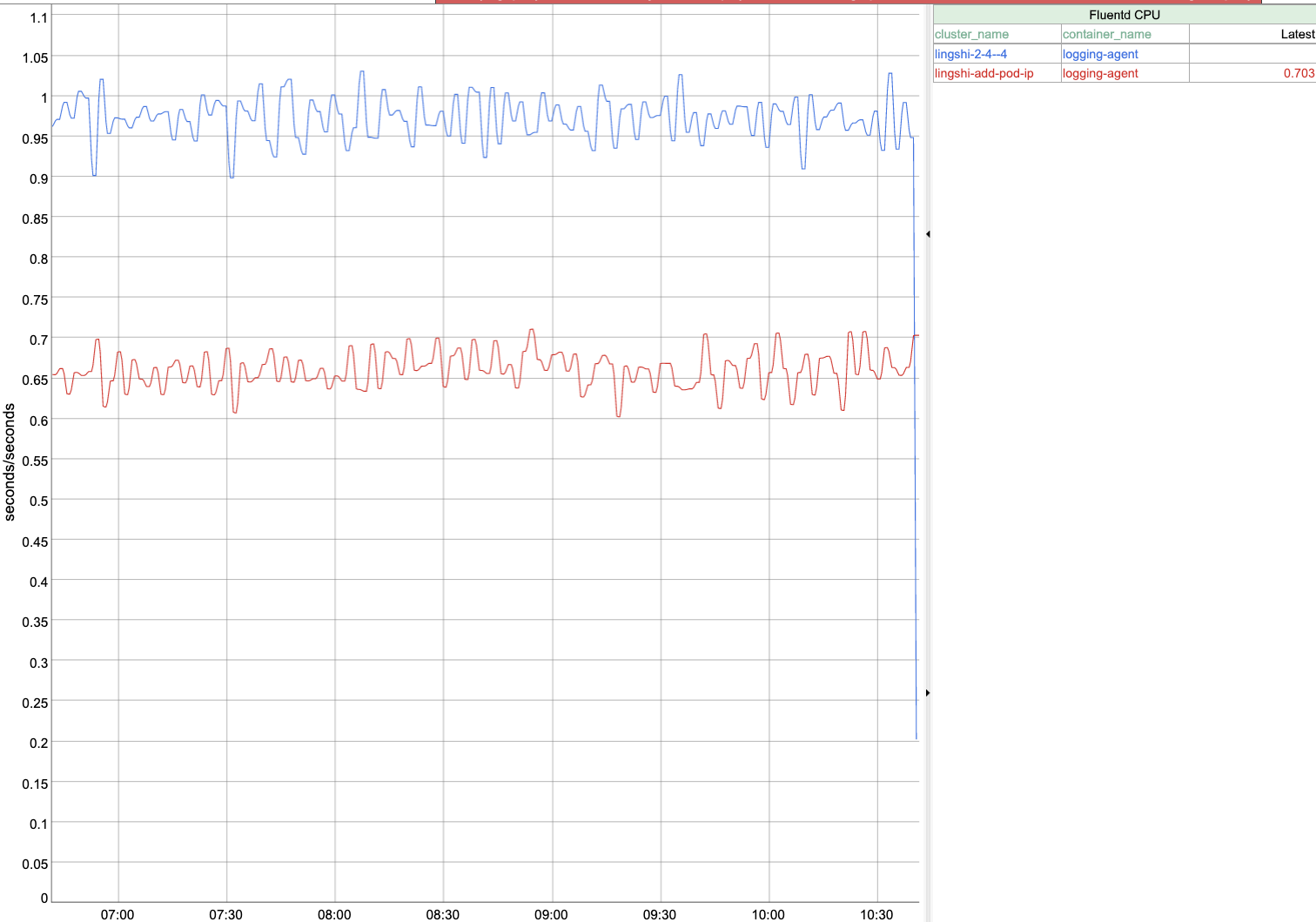

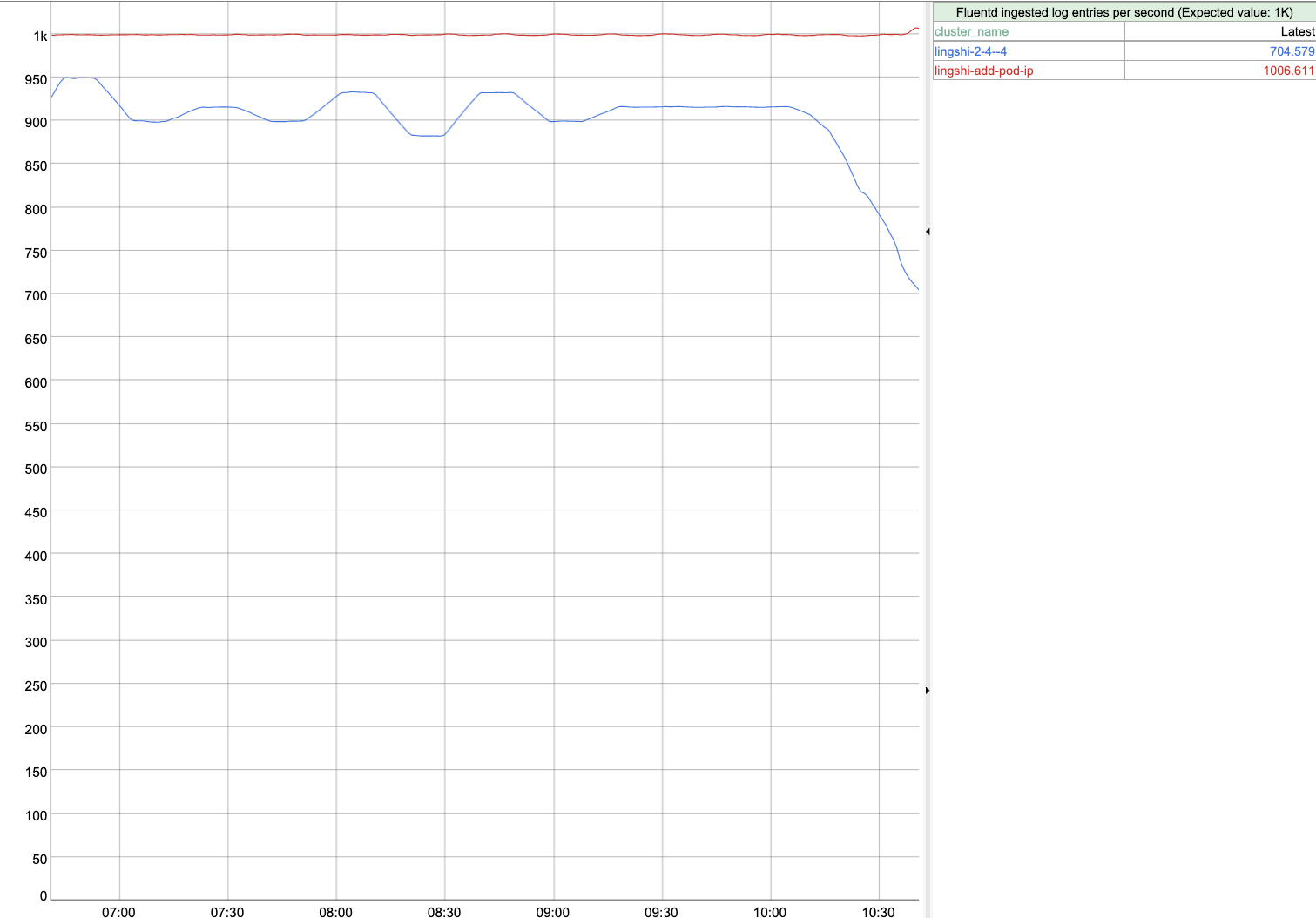


|
@qingling128 great work! |
|
Thank you! I've verified the performance again as shown below after #219 got merged.
CPU memory log throughput retries are functional @jcantrill - Now that it looks all good, could you help create a new release when you get a sec? |

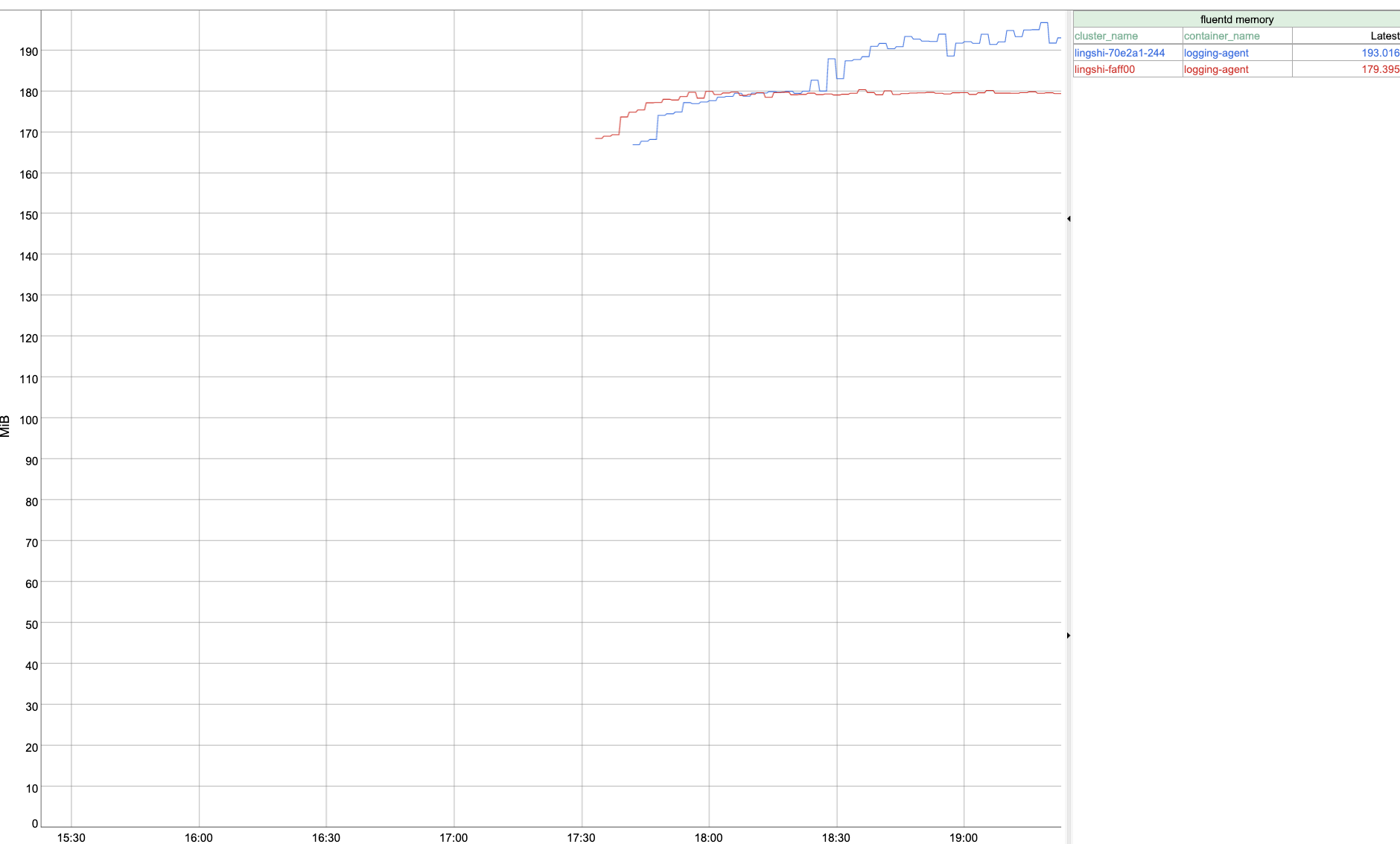


fixes #213